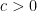You need to know: Basic probability theory, random vector in , independent and identically distributed (i.i.d.) random vectors, Gaussian distribution in , covariance matrix, non-singular matrix, overwhelming probability, hyperplane in .
Background: Let be a random point cloud consisting of points , sampled independently and identically from a Gaussian distribution in with non-singular covariance matrix. Set is called linearly separable (or 1-convex) if every point in it can be separated from other points by a hyperplane.
The Theorem: On 5th July 2006, David Donoho and Jared Tanner submitted to the Journal of the AMS a paper in which they proved, among other results, that for any , with overwhelming probability for large , each subset of of size at most can be separated from other points of by a hyperplane.
Short context: If you select n random points on the plane, then, if n is not too small, you will likely to find a point which is in the convex hull of the other points, and therefore cannot be separated from them by a line. The theorem states that (at least for Gaussian distribution), the situation in high dimension is dramatically different: with very high probability, every group of points can be separated from others by a hyperplane. In particular, set of n points is linearly separable if , or for some . The Theorem has many applications, to, for example, developing efficient error-correction mechanisms, sparse signal recovery, etc.
Links: Free arxiv version of the original paper is here, journal version is here.