You need to know: Graph, infinite graph, connected graphs, connected components of a graph, degree of a vertex in a graph, basic probability theory, almost sure convergence, infimum, notation |A| for the number of elements in any finite set A.
Background: Let  be an infinite graph. Graph
be an infinite graph. Graph  is called locally finite if every vertex
is called locally finite if every vertex  has finite degree. An automorphism of graph is a bijection
has finite degree. An automorphism of graph is a bijection  , such that pair of vertices
, such that pair of vertices  is an edge if and only if
is an edge if and only if  is an edge. For vertices
is an edge. For vertices  , let us write
, let us write  if there is an automorphism
if there is an automorphism  such that
such that  . An (infinite) graph G is called quasi-transitive if its vertex set V can be partitioned into finitely many classes
. An (infinite) graph G is called quasi-transitive if its vertex set V can be partitioned into finitely many classes  , such that if and only if vertices u and v belong to the same class
, such that if and only if vertices u and v belong to the same class 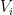 . Let
. Let  be the set of vertices
be the set of vertices 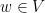 such that there is an automorphism such that
such that there is an automorphism such that  and
and  . A graph G is called unimodular if
. A graph G is called unimodular if  whenever , and nonunimodular otherwise.
whenever , and nonunimodular otherwise.
Let ![p\in[0,1]](https://s0.wp.com/latex.php?latex=p%5Cin%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) . The Bernoulli(p) bond percolation on is a subgraph of G to which each edge of G is included independently with probability p. For given G, let
. The Bernoulli(p) bond percolation on is a subgraph of G to which each edge of G is included independently with probability p. For given G, let  be the infimum of all such that the Bernoulli(p) bond percolation on G has an infinite connected component almost surely, and let
be the infimum of all such that the Bernoulli(p) bond percolation on G has an infinite connected component almost surely, and let  be the infimum of all p for which this infinite connected component is unique almost surely.
be the infimum of all p for which this infinite connected component is unique almost surely.
The Theorem: On 7th November 2017, Tom Hutchcroft submitted to the Journal of the AMS a paper in which he proved, among other results, that for any connected, locally finite, quasi-transitive, nonunimodular graph G, we have  .
.
Short context: Inequality implies the existence of non-empty range of parameters  such that Bernoulli(p) bond percolation on G has many infinite connected components. Characterisation of graphs with this property is a well-known important open problem. In 1996, Benjamini and Schramm conjectured that a connected, locally finite, quasi-transitive graph has if and inly if it is nonamenable, see here for the definition. In fact, Gandolfi, Keane, and Newman proved the “only if” part in 1992, so only the “if” part remains open. The proof of this theorem can be extended to quasi-transitive graphs, and this implies the Benjamini-Schramm conjecture for planar graphs. The Theorem confirms the conjecture for nonunimodular graphs.
such that Bernoulli(p) bond percolation on G has many infinite connected components. Characterisation of graphs with this property is a well-known important open problem. In 1996, Benjamini and Schramm conjectured that a connected, locally finite, quasi-transitive graph has if and inly if it is nonamenable, see here for the definition. In fact, Gandolfi, Keane, and Newman proved the “only if” part in 1992, so only the “if” part remains open. The proof of this theorem can be extended to quasi-transitive graphs, and this implies the Benjamini-Schramm conjecture for planar graphs. The Theorem confirms the conjecture for nonunimodular graphs.
Links: Free arxiv version of the original paper is here, journal version is here.
Go to the list of all theorems
 of dimension
of dimension  , Euclidean norm
, Euclidean norm  of vector
of vector  , (second) derivative of a function
, (second) derivative of a function  , small o notation
, small o notation  .
. and positions
and positions  at time
at time  are moving according to Newton’s laws of motion:
are moving according to Newton’s laws of motion:  , where
, where  is the distance between
is the distance between  and
and 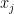 . The motion of particles is determined by the initial conditions: their masses and their positions and velocities at time
. The motion of particles is determined by the initial conditions: their masses and their positions and velocities at time 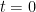 . Let
. Let 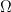 be the set of configurations such that the motion has no collisions (
be the set of configurations such that the motion has no collisions ( for all
for all 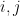 and
and  and
and  whenever
whenever 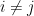 .
. 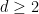 , there are hyperbolic motions
, there are hyperbolic motions  such that
such that  as
as  for any choice of
for any choice of  , for any
, for any  normalized by
normalized by  , and for any constant
, and for any constant  .
.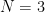 , but can we at least understand hyperbolic motions? The only explicitly known hyperbolic motions are such that the shape of the configuration does not change with time, but it is conjectured that there are only finitely many such motions for any fixed
, but can we at least understand hyperbolic motions? The only explicitly known hyperbolic motions are such that the shape of the configuration does not change with time, but it is conjectured that there are only finitely many such motions for any fixed  . In contrast, the Theorem states that hyperbolic motions exist for all initial configurations and all choices of the limited velocities.
. In contrast, the Theorem states that hyperbolic motions exist for all initial configurations and all choices of the limited velocities. 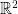 , (second) derivative of a function
, (second) derivative of a function  .
. are moving according to Newton’s laws of motion:
are moving according to Newton’s laws of motion:  , where
, where 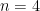 , there is a non-empty set of initial conditions, such that all four points escape to infinity in a finite time, avoiding collisions.
, there is a non-empty set of initial conditions, such that all four points escape to infinity in a finite time, avoiding collisions.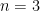 , but can we at least understand under what initial conditions the solution to the system of Newton equations (presented above) is well-defined for all
, but can we at least understand under what initial conditions the solution to the system of Newton equations (presented above) is well-defined for all  ? This may be not the case for two reasons: (a) collision happened, and (b) there are no collisions but a point escape to infinity in a finite time. Case (b) is known as non-collision singularity. In 1897, Painlevé proved that there are no such singularities for
? This may be not the case for two reasons: (a) collision happened, and (b) there are no collisions but a point escape to infinity in a finite time. Case (b) is known as non-collision singularity. In 1897, Painlevé proved that there are no such singularities for  . In 1992, Xia proved this conjecture (for motions in
. In 1992, Xia proved this conjecture (for motions in 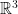 ) for
) for 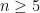 . The Theorem establishes the remaining (and the hardest) case
. The Theorem establishes the remaining (and the hardest) case ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) a cake, and any finite union of subintervals of
a cake, and any finite union of subintervals of 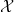 be the set of all pieces of cake. Let
be the set of all pieces of cake. Let  be the set of agents, each agent i having its own valuation function
be the set of agents, each agent i having its own valuation function  such that (i)
such that (i)  for all disjoint
for all disjoint  , and (ii) for every
, and (ii) for every  and
and  , there exists
, there exists  in
in  . A cake allocation is a partition
. A cake allocation is a partition ![[0,1]=\bigcup\limits_{i=1}^n X_i](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%3D%5Cbigcup%5Climits_%7Bi%3D1%7D%5En+X_i&bg=ffffff&fg=000000&s=0&c=20201002) into disjoint pieces
into disjoint pieces  . We say that agent i is envious if
. We say that agent i is envious if  for some j. A discrete protocol is an algorithm which returns an allocation after a sequence of queries which either (1) for given
for some j. A discrete protocol is an algorithm which returns an allocation after a sequence of queries which either (1) for given ![x \in [0,1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) and
and  , ask agent i to return a point
, ask agent i to return a point ![y\in[0,1]](https://s0.wp.com/latex.php?latex=y%5Cin%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) such that
such that ![V_i([x,y])=r](https://s0.wp.com/latex.php?latex=V_i%28%5Bx%2Cy%5D%29%3Dr&bg=ffffff&fg=000000&s=0&c=20201002) (CUT query), or (2) for given
(CUT query), or (2) for given ![x,y\in[0,1]](https://s0.wp.com/latex.php?latex=x%2Cy%5Cin%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) , ask agent i to return
, ask agent i to return ![V_i([x,y])](https://s0.wp.com/latex.php?latex=V_i%28%5Bx%2Cy%5D%29&bg=ffffff&fg=000000&s=0&c=20201002) (EVALUATE query). A protocol is called envy-free if no agent is envious if he/she follows the protocol truthfully. A protocol is bounded if the number of queries required to return a solution is bounded by a constant
(EVALUATE query). A protocol is called envy-free if no agent is envious if he/she follows the protocol truthfully. A protocol is bounded if the number of queries required to return a solution is bounded by a constant 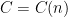 depending only on n but not on
depending only on n but not on  . In 2015, Aziz and Mackenzie solved the problem for
. In 2015, Aziz and Mackenzie solved the problem for  has a weight
has a weight ![b_{vw}\in[0,1]](https://s0.wp.com/latex.php?latex=b_%7Bvw%7D%5Cin%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Each vertex v has a threshold
. Each vertex v has a threshold  , and the thresholds
, and the thresholds  , we select some set A of vertices at mark them as “active”. At times
, we select some set A of vertices at mark them as “active”. At times  , vertex v become active if
, vertex v become active if  , and if vertex become active at stays active forever. This process ends if no activations occur from round
, and if vertex become active at stays active forever. This process ends if no activations occur from round  . The influence
. The influence  of a set A of vertices is the expected number of active nodes at the end of the process. The influence maximization problem asks, given graph G, weights
of a set A of vertices is the expected number of active nodes at the end of the process. The influence maximization problem asks, given graph G, weights  , and parameter k, to find a k-vertex set A with maximal
, and parameter k, to find a k-vertex set A with maximal  , there is a polynomial-time algorithm approximating the maximum influence to within a factor of
, there is a polynomial-time algorithm approximating the maximum influence to within a factor of  , where
, where  is the base of the natural logarithm.
is the base of the natural logarithm.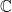 , absolute value
, absolute value 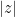 of
of  , set
, set  of vectors with n complex coordinates, inner product
of vectors with n complex coordinates, inner product  in
in  , and let
, and let  be vectors independently and uniformly sampled from the unit sphere in
be vectors independently and uniformly sampled from the unit sphere in  are called magnitude measurements of x.
are called magnitude measurements of x.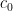 and
and 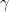 such that an arbitrary
such that an arbitrary  magnitude measurements in polynomial time with probability at least
magnitude measurements in polynomial time with probability at least  .
. represent measurements. In many applications, only the absolute value of
represent measurements. In many applications, only the absolute value of 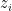 are fixed and given, the problem of recovering x from
are fixed and given, the problem of recovering x from 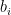 may be computationally infeasible. The Theorem states, however, that we can select
may be computationally infeasible. The Theorem states, however, that we can select 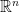 , inner product
, inner product  for
for  , norm
, norm  , proper convex lower-semicontinuous (l.s.c.) function
, proper convex lower-semicontinuous (l.s.c.) function ![F:{\mathbb R}^n \to [0,+\infty]](https://s0.wp.com/latex.php?latex=F%3A%7B%5Cmathbb+R%7D%5En+%5Cto+%5B0%2C%2B%5Cinfty%5D&bg=ffffff&fg=000000&s=0&c=20201002) , continuous linear operator
, continuous linear operator  , its norm
, its norm  .
.![G:{\mathbb R}^n \to [0,+\infty]](https://s0.wp.com/latex.php?latex=G%3A%7B%5Cmathbb+R%7D%5En+%5Cto+%5B0%2C%2B%5Cinfty%5D&bg=ffffff&fg=000000&s=0&c=20201002) and
and ![F:{\mathbb R}^m \to [0,+\infty]](https://s0.wp.com/latex.php?latex=F%3A%7B%5Cmathbb+R%7D%5Em+%5Cto+%5B0%2C%2B%5Cinfty%5D&bg=ffffff&fg=000000&s=0&c=20201002) be proper convex l.s.c. functions, and let
be proper convex l.s.c. functions, and let  be the convex conjugate of F. Let
be the convex conjugate of F. Let  be such that
be such that  for all
for all  ,
,  . Let
. Let  . By saddle-point problem we mean the problem of the form
. By saddle-point problem we mean the problem of the form  . A pair
. A pair  is called a saddle-point of this problem if
is called a saddle-point of this problem if  for all
for all  and
and  for all
for all  . For any
. For any ![V:{\mathbb R}^n \to [0,+\infty]](https://s0.wp.com/latex.php?latex=V%3A%7B%5Cmathbb+R%7D%5En+%5Cto+%5B0%2C%2B%5Cinfty%5D&bg=ffffff&fg=000000&s=0&c=20201002) ,
,  , and
, and 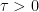 , denote
, denote  . For
. For  ,
, ![\theta\in[0,1]](https://s0.wp.com/latex.php?latex=%5Ctheta%5Cin%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) , initial points
, initial points  ,
,  , and
, and  , define sequences
, define sequences  iteratively as follows:
iteratively as follows:  ,
,  ,
,  ,
,  .
.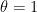 and
and  , then there exist a saddle-point
, then there exist a saddle-point  and
and  .
.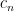 the number of n-step self-avoiding (that is, visiting every vertex at most once) walks on the honeycomb lattice H started from some fixed vertex. It is known that there exists
the number of n-step self-avoiding (that is, visiting every vertex at most once) walks on the honeycomb lattice H started from some fixed vertex. It is known that there exists  such that
such that ![\mu=\lim\limits_{n\to\infty} \sqrt[n]{c_n}](https://s0.wp.com/latex.php?latex=%5Cmu%3D%5Clim%5Climits_%7Bn%5Cto%5Cinfty%7D+%5Csqrt%5Bn%5D%7Bc_n%7D&bg=ffffff&fg=000000&s=0&c=20201002) . This constant
. This constant  is called the connective constant of the honeycomb lattice.
is called the connective constant of the honeycomb lattice. .
.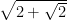 . The Theorem confirms this prediction.
. The Theorem confirms this prediction. of
of  , real matrix L (matrix with real entries
, real matrix L (matrix with real entries  ), matrix multiplication, square matrix, l1 norm
), matrix multiplication, square matrix, l1 norm  of matrix L, support set of L (set of pairs
of matrix L, support set of L (set of pairs 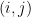 such that
such that  ), diagonal matrix D, identity matrix I, transpose
), diagonal matrix D, identity matrix I, transpose  of matrix L, orthonormal matrix (such that
of matrix L, orthonormal matrix (such that  ) singular value decomposition of a square matrix L (writing
) singular value decomposition of a square matrix L (writing  where D is the diagonal matrix and
where D is the diagonal matrix and  are orthonormal matrices), rank of the matrix L (the number of non-zero entries of D), nuclear norm
are orthonormal matrices), rank of the matrix L (the number of non-zero entries of D), nuclear norm  of L (sum of all entries of D).
of L (sum of all entries of D). be a fixed real number. Let
be a fixed real number. Let  be a vector with
be a vector with  -th component
-th component  and others
and others 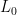 be a real
be a real 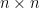 matrix of rank r whose singular value decomposition
matrix of rank r whose singular value decomposition  satisfies (i)
satisfies (i)  , (ii)
, (ii)  , and (iii)
, and (iii)  , where
, where 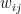 are entries of matrix
are entries of matrix  . Let
. Let  be a fixed
be a fixed 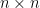 matrix with
matrix with 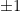 entries
entries  . Choose integer
. Choose integer  . Let
. Let 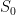 be
be ![[S_0]_{ij}](https://s0.wp.com/latex.php?latex=%5BS_0%5D_%7Bij%7D&bg=ffffff&fg=000000&s=0&c=20201002) whose support set
whose support set  . Let
. Let  . Let
. Let 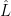 ,
,  be the solution to optimization problem
be the solution to optimization problem  subject to
subject to  .
. ,
,  ,
,  such that with probability at least
such that with probability at least  (over the choice of support of
(over the choice of support of  and
and  provided that
provided that  and
and  .
. as well.
as well.