You need to know: Euclidean space  with scalar product
with scalar product  , norms
, norms  ,
,  , and
, and  in , support of vector
in , support of vector  (subset
(subset  such that
such that 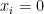 for all
for all  ),
),  matrix, matrix multiplication, notation
matrix, matrix multiplication, notation  for the transpose of matrix
for the transpose of matrix  , big O notation, linear programming, basic probability, mean, variance, independent identically distributed (i.i.d.) random variables, normal distribution
, big O notation, linear programming, basic probability, mean, variance, independent identically distributed (i.i.d.) random variables, normal distribution  with mean
with mean  and variance
and variance  .
.
Background: A vector  is called S-sparse if it is supported on
is called S-sparse if it is supported on  with
with  . For let
. For let  , where A is matrix (
, where A is matrix ( ) and
) and  is a random error (noise) whose components
is a random error (noise) whose components  are i.i.d. and follow
are i.i.d. and follow  . The Dantzig selector
. The Dantzig selector  is a solution to the problem
is a solution to the problem  subject to
subject to  , where
, where  is a constant.
is a constant.
For , let  be
be  submatrix of A formed from the columns of A corresponding to the indices in T. For
submatrix of A formed from the columns of A corresponding to the indices in T. For  , let
, let  be the smallest number such that inequalities
be the smallest number such that inequalities  hold for all T with
hold for all T with  and all
and all  . Also, for
. Also, for  , such that
, such that  , let
, let  be the smallest number such that inequality
be the smallest number such that inequality  holds for all disjoint sets
holds for all disjoint sets  with and
with and  and all ,
and all ,  .
.
The Theorem: On 5th June 2005, Emmanuel Candes and Terence Tao submitted to arxiv a paper in which they proved the following result. Let A be matrix (), S be such that  , be S-sparse, and
, be S-sparse, and  be the Dantzig selector with
be the Dantzig selector with  for some
for some 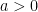 . Then inequality
. Then inequality  , where
, where  , holds with probability exceeding
, holds with probability exceeding  .
.
Short context: In the previous paper, Candes, Romberg, and Tao developed an efficient procedure witch uses the results of a low number ( random measurements suffices) of measurements with arbitrary (random or non-random) error
random measurements suffices) of measurements with arbitrary (random or non-random) error  , to recover S-sparse vector with error
, to recover S-sparse vector with error  . With arbitrary , this result is optimal. The Theorem, however, states that with random measurement error (which often the case in the applications) we can recover
. With arbitrary , this result is optimal. The Theorem, however, states that with random measurement error (which often the case in the applications) we can recover 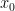 with even higher accuracy
with even higher accuracy  with high probability using the Dantzig selector , which can be computed using linear programming. The error in the Theorem is optimal up to the constant and
with high probability using the Dantzig selector , which can be computed using linear programming. The error in the Theorem is optimal up to the constant and  factors.
factors.
Links: Free arxiv version of the original paper is here, journal version is here.
Go to the list of all theorems
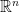













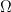



 of vector x, matrix multiplication, algorithms and their running times, polynomial algorithm, polynomial-time reduction, complexity classes P and PPAD (Polynomial Parity Arguments on Directed graphs), PPAD-complete problem.
of vector x, matrix multiplication, algorithms and their running times, polynomial algorithm, polynomial-time reduction, complexity classes P and PPAD (Polynomial Parity Arguments on Directed graphs), PPAD-complete problem. be the set of vectors
be the set of vectors  such that all
such that all  and
and  . The problem of computing a two-player Nash equilibrium is: given two
. The problem of computing a two-player Nash equilibrium is: given two 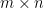 matrices A and B with rational entries, compute vectors
matrices A and B with rational entries, compute vectors  and
and  such that
such that  and
and  for all
for all  and
and  .
. PPAD fails.
PPAD fails. for set of vectors
for set of vectors  with complex
with complex 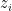 , algorithm, probabilistic algorithm, average running time of an algorithm.
, algorithm, probabilistic algorithm, average running time of an algorithm. be a positive integer. Let H be the space of all systems
be a positive integer. Let H be the space of all systems ![f = [f_1,\dots ,f_n]:{\mathbb C}^n \to {\mathbb C}^n](https://s0.wp.com/latex.php?latex=f+%3D+%5Bf_1%2C%5Cdots+%2Cf_n%5D%3A%7B%5Cmathbb+C%7D%5En+%5Cto+%7B%5Cmathbb+C%7D%5En&bg=ffffff&fg=000000&s=0&c=20201002) on n polynomial equations in n unknowns. For
on n polynomial equations in n unknowns. For  , denote
, denote  the set of solutions of
the set of solutions of  .
. and
and  for some
for some 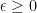 (this is called
(this is called  -regularisation problem).
-regularisation problem). . Then for any
. Then for any  , we have
, we have  , where the constant
, where the constant  depends only on
depends only on  . For example,
. For example,  for
for  and
and  for
for  .
. ) then
) then  . The authors show that the condition
. The authors show that the condition  random measurements. In an earlier work, Donoho
random measurements. In an earlier work, Donoho  in the Theorem is essentially optimal.
in the Theorem is essentially optimal. in
in  be orthonormal basis in
be orthonormal basis in  (where
(where  and
and  are constants) be the set of vectors whose coefficients
are constants) be the set of vectors whose coefficients  in this basis are not too large. Let
in this basis are not too large. Let  has the form
has the form  for some vectors
for some vectors  ,
,  be arbitrary operator, and
be arbitrary operator, and 
 and
and  there is a constant
there is a constant  , such that
, such that  whenever
whenever  .
.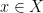
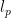 -sparse. Such vectors arise in numerous applications, for example, x may represent an image (e.g. medical image) with m pixels. Vectors
-sparse. Such vectors arise in numerous applications, for example, x may represent an image (e.g. medical image) with m pixels. Vectors  the result of n measurements,
the result of n measurements,  is the worst-case error of this procedure, and
is the worst-case error of this procedure, and  is the minimal worst-case error we can achieve using non-adaptive procedure, that is, the same for all x. The Theorem states that we can achieve
is the minimal worst-case error we can achieve using non-adaptive procedure, that is, the same for all x. The Theorem states that we can achieve  error, where
error, where  , using just
, using just  non-adaptive measurements. This methodology is called compressed sensing and has dramatic implications in, for example, fast reconstruction of medical images. The paper is one of the most cited (if not the most cited) mathematical paper of the 21st century.
non-adaptive measurements. This methodology is called compressed sensing and has dramatic implications in, for example, fast reconstruction of medical images. The paper is one of the most cited (if not the most cited) mathematical paper of the 21st century. , rotations, translations, and dilations in the plane, (second) derivative of a function
, rotations, translations, and dilations in the plane, (second) derivative of a function  , uniform rotation, angular velocity.
, uniform rotation, angular velocity. and positions
and positions  are moving according to Newton’s laws of motion:
are moving according to Newton’s laws of motion:  , where
, where  is the distance between
is the distance between  and
and 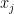 . A relative equilibrium motion is a solution of this system of the form
. A relative equilibrium motion is a solution of this system of the form  where
where  is a uniform rotation with constant angular velocity
is a uniform rotation with constant angular velocity  around some point
around some point  . Two relative equilibria are equivalent if they are related by rotations, translations, and dilations in the plane.
. Two relative equilibria are equivalent if they are related by rotations, translations, and dilations in the plane.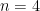 , there is only a finite number of equivalence classes of relative equilibria, for any positive masses
, there is only a finite number of equivalence classes of relative equilibria, for any positive masses  .
.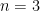 , but can we at least classify “nice” relative equilibrium motions on the plane? This problem is solved for
, but can we at least classify “nice” relative equilibrium motions on the plane? This problem is solved for  , the question whether the number of relative equilibria is finite is a major open problem, which was included as problem 6 into Smale’s list of problems for the 21st century. The Theorem solves this problem for
, the question whether the number of relative equilibria is finite is a major open problem, which was included as problem 6 into Smale’s list of problems for the 21st century. The Theorem solves this problem for  of a matrix u, convergence of sequence of matrices to a limit.
of a matrix u, convergence of sequence of matrices to a limit. matrix u with entries
matrix u with entries  define its total variation as
define its total variation as  where
where  and
and  by convention. For given
by convention. For given 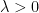 , consider optimization problem
, consider optimization problem  looking for matrix u close to g but with small total variation
looking for matrix u close to g but with small total variation  .
.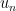 of matrices which is guaranteed to converge to the optimal solution
of matrices which is guaranteed to converge to the optimal solution  of this problem.
of this problem.![E[.]](https://s0.wp.com/latex.php?latex=E%5B.%5D&bg=ffffff&fg=000000&s=0&c=20201002) ), independent random variables, identically distributed random variables.
), independent random variables, identically distributed random variables. , its Shannon entropy is
, its Shannon entropy is  . Random variable X is square-integrable if
. Random variable X is square-integrable if ![E[X^2]<\infty](https://s0.wp.com/latex.php?latex=E%5BX%5E2%5D%3C%5Cinfty&bg=ffffff&fg=000000&s=0&c=20201002) .
.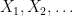 of independent and identically distributed square-integrable random variables, the entropy of the normalised sum
of independent and identically distributed square-integrable random variables, the entropy of the normalised sum  is a non-decreasing function of n.
is a non-decreasing function of n. converge to normal distribution. In 1949 Shannon proved that
converge to normal distribution. In 1949 Shannon proved that  . In 1978, Lieb conjectured that in fact
. In 1978, Lieb conjectured that in fact  for all n, which could be interpreted that
for all n, which could be interpreted that 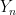 becomes closer and closer to the normal distribution (the one with maximal entropy) at every step. This conjecture was open even for
becomes closer and closer to the normal distribution (the one with maximal entropy) at every step. This conjecture was open even for 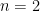 . The Theorems proves it in full.
. The Theorems proves it in full.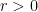 . The agents are called neighbours at time t if the distance between them is at most r. At discrete time moments
. The agents are called neighbours at time t if the distance between them is at most r. At discrete time moments  each agent’s direction is updated and become the average of its own direction and the directions of its neighbours. At any time moment t, let
each agent’s direction is updated and become the average of its own direction and the directions of its neighbours. At any time moment t, let  be a graph with vertices being agents, in which neighbours connected by edges.
be a graph with vertices being agents, in which neighbours connected by edges. ,
,  , starting at
, starting at 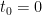 , in which graph
, in which graph 