You need to know: Graph, infinite graph, connected graphs, connected components of a graph, degree of a vertex in a graph, basic probability theory, almost sure convergence, infimum, notation |A| for the number of elements in any finite set A.
Background: Let  be an infinite graph. Graph
be an infinite graph. Graph  is called locally finite if every vertex
is called locally finite if every vertex  has finite degree. An automorphism of graph is a bijection
has finite degree. An automorphism of graph is a bijection  , such that pair of vertices
, such that pair of vertices  is an edge if and only if
is an edge if and only if  is an edge. For vertices
is an edge. For vertices  , let us write
, let us write  if there is an automorphism
if there is an automorphism  such that
such that  . An (infinite) graph G is called quasi-transitive if its vertex set V can be partitioned into finitely many classes
. An (infinite) graph G is called quasi-transitive if its vertex set V can be partitioned into finitely many classes  , such that if and only if vertices u and v belong to the same class
, such that if and only if vertices u and v belong to the same class 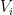 . Let
. Let  be the set of vertices
be the set of vertices 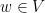 such that there is an automorphism such that
such that there is an automorphism such that  and
and  . A graph G is called unimodular if
. A graph G is called unimodular if  whenever , and nonunimodular otherwise.
whenever , and nonunimodular otherwise.
Let ![p\in[0,1]](https://s0.wp.com/latex.php?latex=p%5Cin%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) . The Bernoulli(p) bond percolation on is a subgraph of G to which each edge of G is included independently with probability p. For given G, let
. The Bernoulli(p) bond percolation on is a subgraph of G to which each edge of G is included independently with probability p. For given G, let  be the infimum of all such that the Bernoulli(p) bond percolation on G has an infinite connected component almost surely, and let
be the infimum of all such that the Bernoulli(p) bond percolation on G has an infinite connected component almost surely, and let  be the infimum of all p for which this infinite connected component is unique almost surely.
be the infimum of all p for which this infinite connected component is unique almost surely.
The Theorem: On 7th November 2017, Tom Hutchcroft submitted to the Journal of the AMS a paper in which he proved, among other results, that for any connected, locally finite, quasi-transitive, nonunimodular graph G, we have  .
.
Short context: Inequality implies the existence of non-empty range of parameters  such that Bernoulli(p) bond percolation on G has many infinite connected components. Characterisation of graphs with this property is a well-known important open problem. In 1996, Benjamini and Schramm conjectured that a connected, locally finite, quasi-transitive graph has if and inly if it is nonamenable, see here for the definition. In fact, Gandolfi, Keane, and Newman proved the “only if” part in 1992, so only the “if” part remains open. The proof of this theorem can be extended to quasi-transitive graphs, and this implies the Benjamini-Schramm conjecture for planar graphs. The Theorem confirms the conjecture for nonunimodular graphs.
such that Bernoulli(p) bond percolation on G has many infinite connected components. Characterisation of graphs with this property is a well-known important open problem. In 1996, Benjamini and Schramm conjectured that a connected, locally finite, quasi-transitive graph has if and inly if it is nonamenable, see here for the definition. In fact, Gandolfi, Keane, and Newman proved the “only if” part in 1992, so only the “if” part remains open. The proof of this theorem can be extended to quasi-transitive graphs, and this implies the Benjamini-Schramm conjecture for planar graphs. The Theorem confirms the conjecture for nonunimodular graphs.
Links: Free arxiv version of the original paper is here, journal version is here.
Go to the list of all theorems




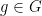


![\mu:G\to[0,1]](https://s0.wp.com/latex.php?latex=%5Cmu%3AG%5Cto%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002)
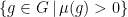
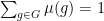

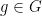
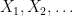

![{\mathbb P}[X_i=g]=\mu(g)](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb+P%7D%5BX_i%3Dg%5D%3D%5Cmu%28g%29&bg=ffffff&fg=000000&s=0&c=20201002)



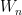
![L_\mu(n) = {\mathbb E}[|W_n|] = \sum_{g\in G}|g|{\mathbb P}[W_n=g]](https://s0.wp.com/latex.php?latex=L_%5Cmu%28n%29+%3D+%7B%5Cmathbb+E%7D%5B%7CW_n%7C%5D+%3D+%5Csum_%7Bg%5Cin+G%7D%7Cg%7C%7B%5Cmathbb+P%7D%5BW_n%3Dg%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![H_\mu(n) = - \sum_{g\in G}{\mathbb P}[W_n=g]\log{\mathbb P}[W_n=g]](https://s0.wp.com/latex.php?latex=H_%5Cmu%28n%29+%3D+-+%5Csum_%7Bg%5Cin+G%7D%7B%5Cmathbb+P%7D%5BW_n%3Dg%5D%5Clog%7B%5Cmathbb+P%7D%5BW_n%3Dg%5D&bg=ffffff&fg=000000&s=0&c=20201002)

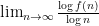
![\gamma\in[1/2,1]](https://s0.wp.com/latex.php?latex=%5Cgamma%5Cin%5B1%2F2%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\theta\in[1/2,1]](https://s0.wp.com/latex.php?latex=%5Ctheta%5Cin%5B1%2F2%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002)

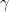

![\gamma,\theta\in[3/4,1]](https://s0.wp.com/latex.php?latex=%5Cgamma%2C%5Ctheta%5Cin%5B3%2F4%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002)
 denote random graph with n vertices, such that every possible edge is included independently with probability p.
denote random graph with n vertices, such that every possible edge is included independently with probability p. 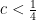 , there is no sequence of intervals of length
, there is no sequence of intervals of length  which contain
which contain  with high probability.
with high probability.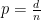 for constant d, then, with probability that tends to 1 as
for constant d, then, with probability that tends to 1 as 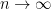 , the chromatic number of
, the chromatic number of 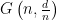 is either
is either  or
or 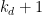 , where
, where  . The Theorem states that if
. The Theorem states that if 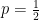 is a constant, then
is a constant, then  of square matrix M, singular square matrix (matrix with determinant
of square matrix M, singular square matrix (matrix with determinant  ), basic probability theory, independent and identically distributed (i.i.d.) random variables,
), basic probability theory, independent and identically distributed (i.i.d.) random variables,  notation.
notation.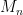 be a random
be a random 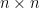 matrix whose entries are i.i.d. Bernoulli random variables (each entry is equal to
matrix whose entries are i.i.d. Bernoulli random variables (each entry is equal to 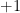 or
or 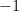 with probabilities
with probabilities  ). Let
). Let  be the probability that
be the probability that  as
as  has attracted considerable attention in literature. There is an obvious lower bound
has attracted considerable attention in literature. There is an obvious lower bound  , and it has been conjectured by many authors that equality holds. For an upper bound, Komlós proved in 1967 that
, and it has been conjectured by many authors that equality holds. For an upper bound, Komlós proved in 1967 that  . In 1995, Kahn, Komlós, and Szemerédi proved that
. In 1995, Kahn, Komlós, and Szemerédi proved that  . This was later improved by Tao and Vu to
. This was later improved by Tao and Vu to  and then to
and then to  , see
, see  . Finally, the Theorem establishes the upper bound
. Finally, the Theorem establishes the upper bound  , which matches the lower bound up to
, which matches the lower bound up to  , Bernoulli convolution
, Bernoulli convolution 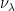 is the distribution of the real random variable
is the distribution of the real random variable  , where the signs are chosen i.i.d. with equal probabilities. It is known that the limit
, where the signs are chosen i.i.d. with equal probabilities. It is known that the limit ![\lim\limits_{r\to 0+}\frac{\log \nu_\lambda([x-r,x+r])}{\log r}](https://s0.wp.com/latex.php?latex=%5Clim%5Climits_%7Br%5Cto+0%2B%7D%5Cfrac%7B%5Clog+%5Cnu_%5Clambda%28%5Bx-r%2Cx%2Br%5D%29%7D%7B%5Clog+r%7D&bg=ffffff&fg=000000&s=0&c=20201002) exists and is constant for
exists and is constant for  . A real number
. A real number  is called algebraic if it is a root of a non-zero polynomial equation with rational coefficients, and is called transcendental otherwise.
is called algebraic if it is a root of a non-zero polynomial equation with rational coefficients, and is called transcendental otherwise. for all transcendental
for all transcendental 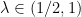 .
. the resulting probability measure
the resulting probability measure  has Lebesgue measure
has Lebesgue measure ![[n]=\{1,2,\dots,n\}](https://s0.wp.com/latex.php?latex=%5Bn%5D%3D%5C%7B1%2C2%2C%5Cdots%2Cn%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002) , and let
, and let  be the set of vectors
be the set of vectors  with each
with each  being either
being either  . Assume that we select each
. Assume that we select each  with some probability
with some probability  , such that
, such that  . For
. For  , define
, define ![{\mathbb P}[A]=\sum\limits_{w\in A}{\mathbb P}(w)](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb+P%7D%5BA%5D%3D%5Csum%5Climits_%7Bw%5Cin+A%7D%7B%5Cmathbb+P%7D%28w%29&bg=ffffff&fg=000000&s=0&c=20201002) . For any function
. For any function  , define expectation
, define expectation  and variance
and variance  . For
. For  , let
, let  . A function
. A function  is called increasing if
is called increasing if  whenever
whenever  coordinate-wise. A probability
coordinate-wise. A probability  is monotonic if for any
is monotonic if for any ![i\in[n]](https://s0.wp.com/latex.php?latex=i%5Cin%5Bn%5D&bg=ffffff&fg=000000&s=0&c=20201002) , any
, any ![F\subset [n]](https://s0.wp.com/latex.php?latex=F%5Csubset+%5Bn%5D&bg=ffffff&fg=000000&s=0&c=20201002) , and any
, and any  satisfying
satisfying  ,
, ![{\mathbb P}[w_j=x_j, \, \forall j \in F]>0](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb+P%7D%5Bw_j%3Dx_j%2C+%5C%2C+%5Cforall+j+%5Cin+F%5D%3E0&bg=ffffff&fg=000000&s=0&c=20201002) and
and ![{\mathbb P}[w_j=y_j, \, \forall j \in F]>0](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb+P%7D%5Bw_j%3Dy_j%2C+%5C%2C+%5Cforall+j+%5Cin+F%5D%3E0&bg=ffffff&fg=000000&s=0&c=20201002) , we have
, we have ![{\mathbb P}[w_i=1 | w_j=x_j, \, \forall j \in F] \leq {\mathbb P}[w_i=1 | w_j=y_j, \, \forall j \in F]](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb+P%7D%5Bw_i%3D1+%7C+w_j%3Dx_j%2C+%5C%2C+%5Cforall+j+%5Cin+F%5D+%5Cleq+%7B%5Cmathbb+P%7D%5Bw_i%3D1+%7C+w_j%3Dy_j%2C+%5C%2C+%5Cforall+j+%5Cin+F%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
. by querying the values of
by querying the values of  . The algorithm stops when it can determine
. The algorithm stops when it can determine  from the bits it has. Let
from the bits it has. Let  be the probability that T, starting from random input
be the probability that T, starting from random input  , queries bit
, queries bit ![f:X\to[0,1]](https://s0.wp.com/latex.php?latex=f%3AX%5Cto%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) , any monotonic probability
, any monotonic probability  .
.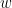 to depend on each other, and instead imposes much weaker condition that the probability
to depend on each other, and instead imposes much weaker condition that the probability  for probability, random variable, distribution of a random variable, independent identically distributed (i.i.d.) random variables, polynomial, degree of a polynomial, monic polynomial. You also need Lebesgue measure and Hausdorff dimension to understand the context.
for probability, random variable, distribution of a random variable, independent identically distributed (i.i.d.) random variables, polynomial, degree of a polynomial, monic polynomial. You also need Lebesgue measure and Hausdorff dimension to understand the context. be real numbers, and let
be real numbers, and let  be a sequence of i.i.d. random variables with
be a sequence of i.i.d. random variables with  and
and  for all n. By
for all n. By  .
.  is called absolutely continuous if there exists function
is called absolutely continuous if there exists function 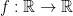 such that
such that  whenever
whenever  . The Mahler measure of any polynomial
. The Mahler measure of any polynomial  is
is  . A real number
. A real number  is called algebraic if
is called algebraic if  for some polynomial P with rational coefficients. The (unique) monic polynomial
for some polynomial P with rational coefficients. The (unique) monic polynomial  of smallest degree with this property is called the minimal polynomial of r. The Mahler measure of r is
of smallest degree with this property is called the minimal polynomial of r. The Mahler measure of r is  .
. and
and  , there is a constant
, there is a constant  such that for any algebraic number
such that for any algebraic number  , the Bernoulli convolution
, the Bernoulli convolution  the
the  is not absolutely continuous for
is not absolutely continuous for  , and also for
, and also for  for some non-empty set
for some non-empty set  . However,
. However,  . The Theorem (with explicit
. The Theorem (with explicit  ) provides a lot of such examples. For example, it implies that
) provides a lot of such examples. For example, it implies that 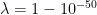 and
and 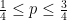 .
. 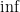 , supremum
, supremum  , limit superior
, limit superior  .
. , where
, where  is the minimal number of intervals of length
is the minimal number of intervals of length  .
. has packing dimension
has packing dimension 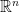 , origin in
, origin in  of a matrix A, inverse
of a matrix A, inverse  of a matrix A with
of a matrix A with  , symmetric matrix, transpose
, symmetric matrix, transpose  of matrix A.
of matrix A.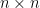 matrix
matrix  is called positive definite, if
is called positive definite, if  for all non-zero
for all non-zero  . Given a positive definite
. Given a positive definite  be a function given by
be a function given by  ,
,  . For a subset
. For a subset  , let
, let  .
.  holds for all convex and centrally symmetric sets
holds for all convex and centrally symmetric sets  .
. for the set of integers, basic probability theory, independence, random variable, stochastic process, almost surely.
for the set of integers, basic probability theory, independence, random variable, stochastic process, almost surely. is k-dependent if the random sequences
is k-dependent if the random sequences  and
and  are independent of each other, for each
are independent of each other, for each  . We call a stochastic process
. We call a stochastic process  takes values in
takes values in  , and almost surely we have
, and almost surely we have  for all
for all  .
. and
and  . The Theorem gives a complete answer to this question.
. The Theorem gives a complete answer to this question.