You need to know: Euclidean space  with scalar product
with scalar product  , norms
, norms  ,
,  , and
, and  in , support of vector
in , support of vector  (subset
(subset  such that
such that 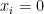 for all
for all  ),
),  matrix, matrix multiplication, notation
matrix, matrix multiplication, notation  for the transpose of matrix
for the transpose of matrix  , big O notation, linear programming, basic probability, mean, variance, independent identically distributed (i.i.d.) random variables, normal distribution
, big O notation, linear programming, basic probability, mean, variance, independent identically distributed (i.i.d.) random variables, normal distribution  with mean
with mean  and variance
and variance  .
.
Background: A vector  is called S-sparse if it is supported on
is called S-sparse if it is supported on  with
with  . For let
. For let  , where A is matrix (
, where A is matrix ( ) and
) and  is a random error (noise) whose components
is a random error (noise) whose components  are i.i.d. and follow
are i.i.d. and follow  . The Dantzig selector
. The Dantzig selector  is a solution to the problem
is a solution to the problem  subject to
subject to  , where
, where  is a constant.
is a constant.
For , let  be
be  submatrix of A formed from the columns of A corresponding to the indices in T. For
submatrix of A formed from the columns of A corresponding to the indices in T. For  , let
, let  be the smallest number such that inequalities
be the smallest number such that inequalities  hold for all T with
hold for all T with  and all
and all  . Also, for
. Also, for  , such that
, such that  , let
, let  be the smallest number such that inequality
be the smallest number such that inequality  holds for all disjoint sets
holds for all disjoint sets  with and
with and  and all ,
and all ,  .
.
The Theorem: On 5th June 2005, Emmanuel Candes and Terence Tao submitted to arxiv a paper in which they proved the following result. Let A be matrix (), S be such that  , be S-sparse, and
, be S-sparse, and  be the Dantzig selector with
be the Dantzig selector with  for some
for some 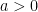 . Then inequality
. Then inequality  , where
, where  , holds with probability exceeding
, holds with probability exceeding  .
.
Short context: In the previous paper, Candes, Romberg, and Tao developed an efficient procedure witch uses the results of a low number ( random measurements suffices) of measurements with arbitrary (random or non-random) error
random measurements suffices) of measurements with arbitrary (random or non-random) error  , to recover S-sparse vector with error
, to recover S-sparse vector with error  . With arbitrary , this result is optimal. The Theorem, however, states that with random measurement error (which often the case in the applications) we can recover
. With arbitrary , this result is optimal. The Theorem, however, states that with random measurement error (which often the case in the applications) we can recover 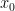 with even higher accuracy
with even higher accuracy  with high probability using the Dantzig selector , which can be computed using linear programming. The error in the Theorem is optimal up to the constant and
with high probability using the Dantzig selector , which can be computed using linear programming. The error in the Theorem is optimal up to the constant and  factors.
factors.
Links: Free arxiv version of the original paper is here, journal version is here.
Go to the list of all theorems

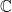




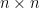




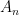







 for probability, random variable, distribution.
for probability, random variable, distribution. from a fixed distribution
from a fixed distribution  . Let
. Let  be the minimum sum of the edge costs of a cycle that visits each vertex precisely once. For any
be the minimum sum of the edge costs of a cycle that visits each vertex precisely once. For any 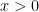 , let
, let  be the unique real number such that
be the unique real number such that  . Let
. Let  .
.![\lim\limits_{n\to \infty}P\left[\left|L_n - L^*\right|>\epsilon\right] = 0.](https://s0.wp.com/latex.php?latex=%5Clim%5Climits_%7Bn%5Cto+%5Cinfty%7DP%5Cleft%5B%5Cleft%7CL_n+-+L%5E%2A%5Cright%7C%3E%5Cepsilon%5Cright%5D+%3D+0.&bg=ffffff&fg=000000&s=0&c=20201002)
![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002) or exponential with mean
or exponential with mean 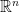 , norm
, norm  of
of  , convex set
, convex set  , convex function on D, probability measure
, convex function on D, probability measure  such that
such that  for every measurable
for every measurable  . If set
. If set  is convex, and
is convex, and  is a convex function on D, then
is a convex function on D, then  , we write
, we write  , and
, and  . Function f is called 1-Lipschitz if
. Function f is called 1-Lipschitz if  for all
for all  . We say that
. We say that  such that for every 1-Lipschitz f we have
such that for every 1-Lipschitz f we have  .
. holds for all
holds for all 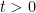 , where c and C are universal constants.
, where c and C are universal constants. is also random and unpredictable. However, if the conclusion of the theorem (known as exponential concentration) holds, then
is also random and unpredictable. However, if the conclusion of the theorem (known as exponential concentration) holds, then  with very high probability. This property looks much stronger than “just” first moment concentration. The Theorem states, however, that these concentrations are in fact equivalent! In fact, in the same paper authors studied several other notions of concentrations, some looks very week and some very strong, and proved that they are all equivalent for the log-concave
with very high probability. This property looks much stronger than “just” first moment concentration. The Theorem states, however, that these concentrations are in fact equivalent! In fact, in the same paper authors studied several other notions of concentrations, some looks very week and some very strong, and proved that they are all equivalent for the log-concave  for length of
for length of  , matrix, matrix multiplication, norm
, matrix, matrix multiplication, norm  of
of  .
. , let
, let  be an
be an 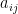 are i.i.d. with the same distribution as X. A random variable X is called subgaussian if there exists constant B such that
are i.i.d. with the same distribution as X. A random variable X is called subgaussian if there exists constant B such that  for all
for all  if
if  does not exist.
does not exist.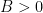 there exist constants
there exist constants  and
and  such that for any subgaussian random variable X with mean
such that for any subgaussian random variable X with mean  , variance
, variance 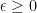 , the probability that
, the probability that  is at most
is at most  .
. is proportional to
is proportional to 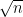 for random matrices with high probability. Before 2007, this was open even if
for random matrices with high probability. Before 2007, this was open even if  takes values
takes values 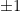 with equal chances (in which case
with equal chances (in which case  . The Theorem proves this conjecture for all matrices with i.i.d. subgaussian entries. Earlier, it was only
. The Theorem proves this conjecture for all matrices with i.i.d. subgaussian entries. Earlier, it was only  is small. Also, the special
is small. Also, the special  case of the Theorem implies
case of the Theorem implies  of integers, probability, independent random variables, exponential distribution, expectation, variance. For
of integers, probability, independent random variables, exponential distribution, expectation, variance. For  , denote
, denote ![[x]](https://s0.wp.com/latex.php?latex=%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002) the largest integer in
the largest integer in ![[0, x]](https://s0.wp.com/latex.php?latex=%5B0%2C+x%5D&bg=ffffff&fg=000000&s=0&c=20201002) if
if  , and the smallest integer in
, and the smallest integer in ![[x, 0]](https://s0.wp.com/latex.php?latex=%5Bx%2C+0%5D&bg=ffffff&fg=000000&s=0&c=20201002) if
if 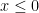 .
.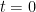 , let us put, for each
, let us put, for each  , a particle in site x, independently and with the same probability
, a particle in site x, independently and with the same probability  . Then, for each particle z, independently generate a random variable
. Then, for each particle z, independently generate a random variable  from exponential distribution with parameter 1, wait for time
from exponential distribution with parameter 1, wait for time  and
and 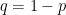 , respectively, provided that the target site is unoccupied (and otherwise stay). This action is then repeated and performed in parallel for all particles. We call this asymmetric simple exclusion process (ASEP). For
, respectively, provided that the target site is unoccupied (and otherwise stay). This action is then repeated and performed in parallel for all particles. We call this asymmetric simple exclusion process (ASEP). For  , let
, let  , where
, where  is the number of particles that began in
is the number of particles that began in ![(-\infty,0]](https://s0.wp.com/latex.php?latex=%28-%5Cinfty%2C0%5D&bg=ffffff&fg=000000&s=0&c=20201002) at time
at time ![[[vt]+1,\infty)](https://s0.wp.com/latex.php?latex=%5B%5Bvt%5D%2B1%2C%5Cinfty%29&bg=ffffff&fg=000000&s=0&c=20201002) at time t, and
at time t, and  is the number of particles that began in
is the number of particles that began in  at time
at time ![(-\infty,[vt]]](https://s0.wp.com/latex.php?latex=%28-%5Cinfty%2C%5Bvt%5D%5D&bg=ffffff&fg=000000&s=0&c=20201002) at time t.
at time t. , there exists positive constants
, there exists positive constants  and
and  , such that
, such that  , for all
, for all  .
. has the meaning of the total net particle current seen by an observer moving at speed v during time interval
has the meaning of the total net particle current seen by an observer moving at speed v during time interval ![[0,t]](https://s0.wp.com/latex.php?latex=%5B0%2Ct%5D&bg=ffffff&fg=000000&s=0&c=20201002) . In 1994, Ferrari and Fontes proved that
. In 1994, Ferrari and Fontes proved that  , which implies that the variance grows linearly in time, except when
, which implies that the variance grows linearly in time, except when 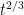 .
. , independent and identically distributed (i.i.d.) random vectors, Gaussian distribution in
, independent and identically distributed (i.i.d.) random vectors, Gaussian distribution in  points
points  , sampled independently and identically from a Gaussian distribution in
, sampled independently and identically from a Gaussian distribution in  , each subset of
, each subset of  can be separated from other points of
can be separated from other points of  , or
, or  for some
for some 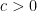 . The Theorem has many applications, to, for example, developing efficient error-correction mechanisms, sparse signal recovery, etc.
. The Theorem has many applications, to, for example, developing efficient error-correction mechanisms, sparse signal recovery, etc. in
in  with a non-empty interior.
with a non-empty interior. converging to
converging to  in
in  , and
, and  such that
such that  where
where  .
. of
of  is close to a normal distribution if n is large. Moreover, the same is true for
is close to a normal distribution if n is large. Moreover, the same is true for  , under some mild conditions on unit vector
, under some mild conditions on unit vector  may be far from being independent.
may be far from being independent.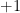 and
and 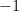 with probability
with probability  each).
each).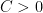 , there are constants B and N such that for any
, there are constants B and N such that for any  the inequality
the inequality  holds with probability at least
holds with probability at least  .
. of its inverse matrix is polynomially bounded with probability at least
of its inverse matrix is polynomially bounded with probability at least  .
. for all
for all 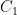 ,
, 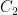 , and
, and  such that for any integer
such that for any integer  , the inequality
, the inequality  holds with probability greater than
holds with probability greater than  .
. if n is large enough. Previously, similar bound was known only if i.i.d. entries
if n is large enough. Previously, similar bound was known only if i.i.d. entries 