You need to know: Prime number, group, identity element, finite group, notation  for the inverse of group element
for the inverse of group element  , subgroup.
, subgroup.
Background: A subgroup S of group G is called normal, if  for any
for any  and
and 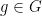 . A group G is called simple if it does not have any normal subgroup, except of itself and
. A group G is called simple if it does not have any normal subgroup, except of itself and 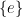 , where is the set consisting on identity element only. A group G is called abelian if
, where is the set consisting on identity element only. A group G is called abelian if  for every and
for every and  , and non-abelian otherwise.
, and non-abelian otherwise.
The Theorem: On 1st May 2015, Robert Guralnick, Martin Liebeck, Eamon O’Brien, Aner Shalev, and Pham Tiep submitted to Inventiones Mathematicae a paper in which they proved the following result. Let p, q be prime numbers, let a, b be non-negative integers, and let 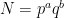 . Then every element g of every finite non-abelian simple group G can be written as
. Then every element g of every finite non-abelian simple group G can be written as  for some
for some  .
.
Short context: Given group G, let w be a map mapping pair into  . Let
. Let  be the set of all
be the set of all 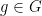 such that
such that  for some
for some  . Map w is called surjective on G if
. Map w is called surjective on G if  . In this language, the Theorem states that w is surjective on every finite non-abelian simple group G. Earlier, this result was proved for commutator map
. In this language, the Theorem states that w is surjective on every finite non-abelian simple group G. Earlier, this result was proved for commutator map  , see here. Also, it is known that
, see here. Also, it is known that  for much broader class of maps w, see here.
for much broader class of maps w, see here.
Links: Free arxiv version of the original paper is here, journal version is here.
Go to the list of all theorems
 , continuous map
, continuous map  , image of a set under map f, polytope, face of a polytope, convex hull, prime numbers, power of a prime.
, image of a set under map f, polytope, face of a polytope, convex hull, prime numbers, power of a prime. , is an m-dimensional polytope which is the convex hull of its
, is an m-dimensional polytope which is the convex hull of its  vertices. The “topological Tverberg conjecture” states that for given integers
vertices. The “topological Tverberg conjecture” states that for given integers  ,
,  ,
,  , and for any continuous map
, and for any continuous map  , there are r pairwise disjoint faces of
, there are r pairwise disjoint faces of  .
.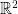 , Lebesgue measurable subsets of
, Lebesgue measurable subsets of  for the translation of set
for the translation of set  by a vector
by a vector  .
. equidecomposable by translations if there are partitions
equidecomposable by translations if there are partitions  and
and  , such that
, such that  ,
,  , for some vectors
, for some vectors  . If, moreover, all
. If, moreover, all 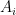 (and thus
(and thus 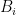 ) are Lebesgue measurable, we say that A and B are equidecomposable by translations with Lebesgue measurable pieces.
) are Lebesgue measurable, we say that A and B are equidecomposable by translations with Lebesgue measurable pieces.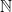 for the set of positive integers, coprime integers.
for the set of positive integers, coprime integers.![f:{\mathbb N} \to [-1,1]](https://s0.wp.com/latex.php?latex=f%3A%7B%5Cmathbb+N%7D+%5Cto+%5B-1%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) is called multiplicative if
is called multiplicative if 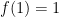 and
and  holds for all coprime
holds for all coprime  .
.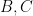 (one can take
(one can take  ) such that for any multiplicative function
) such that for any multiplicative function  , and any
, and any  , inequality
, inequality  folds for all but at most
folds for all but at most  integers
integers ![x\in[X,2X]](https://s0.wp.com/latex.php?latex=x%5Cin%5BX%2C2X%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
. of such function in short intervals of length h. The Theorem states that this is approximately equal to the average
of such function in short intervals of length h. The Theorem states that this is approximately equal to the average  over “long” interval
over “long” interval ![[X,2X]](https://s0.wp.com/latex.php?latex=%5BX%2C2X%5D&bg=ffffff&fg=000000&s=0&c=20201002) , which is much easier to estimate. This has a lot of applications, some of them are derived in the same paper.
, which is much easier to estimate. This has a lot of applications, some of them are derived in the same paper.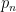 denotes the n-th prime. For
denotes the n-th prime. For  , let
, let 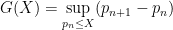 be the largest gap between consecutive primes below X. For
be the largest gap between consecutive primes below X. For  , let
, let  . With notation
. With notation  for the r-th fold logarithm, this simplifies to
for the r-th fold logarithm, this simplifies to  .
.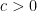 such that
such that  for all X.
for all X. between consecutive primes below X grow with X? It is conjectured that
between consecutive primes below X grow with X? It is conjectured that  , but this is wide open. See
, but this is wide open. See  . For the lower bound, the authors
. For the lower bound, the authors  , giving the first substantial improvement since 1938. The Theorem improves this bound by a
, giving the first substantial improvement since 1938. The Theorem improves this bound by a  factor. The authors argue that this bound in the limit of the current techniques, and a radically new approach will be needed to improve beyond this.
factor. The authors argue that this bound in the limit of the current techniques, and a radically new approach will be needed to improve beyond this. , origin
, origin  , inner product
, inner product  in
in  ), round sphere in
), round sphere in  (set of points on distance r from
(set of points on distance r from  ), surface in
), surface in  be a surface embedded into
be a surface embedded into  , we can build a unit vector
, we can build a unit vector  perpendicular to S, choose any plain P containing
perpendicular to S, choose any plain P containing  at x of a curve which is the intersection of S and P. Let
at x of a curve which is the intersection of S and P. Let  and
and  be the minimum and maximum values of
be the minimum and maximum values of  . Surface S is called a self-similar shrinker if it satisfies the equation
. Surface S is called a self-similar shrinker if it satisfies the equation  for every
for every  if it is connected but cutting it along any closed curve makes it disconnected.
if it is connected but cutting it along any closed curve makes it disconnected. . With notation
. With notation  .
. .
. for some constant
for some constant  by Erdős in 1935, and to
by Erdős in 1935, and to  by Rankin in 1938. This strange-looking bound, surprisingly, standed for almost 80 years, except of improvements by a constant factor. At last, the Theorem proves that
by Rankin in 1938. This strange-looking bound, surprisingly, standed for almost 80 years, except of improvements by a constant factor. At last, the Theorem proves that 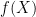 . The same result was proved independently by Maynard. See
. The same result was proved independently by Maynard. See  , origin in
, origin in 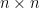 matrix, matrix multiplication, determinant
matrix, matrix multiplication, determinant  of a matrix A, inverse
of a matrix A, inverse  of a matrix A with
of a matrix A with  , symmetric matrix, transpose
, symmetric matrix, transpose  of matrix A.
of matrix A.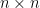 matrix
matrix  is called positive definite, if
is called positive definite, if  for all non-zero
for all non-zero  . Given a positive definite
. Given a positive definite  be a function given by
be a function given by  ,
,  . For a subset
. For a subset  , let
, let  .
.  is called an n-dimensional Gaussian probability measure on
is called an n-dimensional Gaussian probability measure on  holds for all convex and centrally symmetric sets
holds for all convex and centrally symmetric sets  .
. . For any point
. For any point  (called a light source), consider a light ray starting from x and moving inside P, with the usual rule that the angle of incidence equals the angle of reflection. A point
(called a light source), consider a light ray starting from x and moving inside P, with the usual rule that the angle of incidence equals the angle of reflection. A point  there are at most finitely many points
there are at most finitely many points  which are not illuminated from light source x.
which are not illuminated from light source x. be a directed graph, in which each directed edge
be a directed graph, in which each directed edge  has a weight
has a weight ![b_{vw}\in[0,1]](https://s0.wp.com/latex.php?latex=b_%7Bvw%7D%5Cin%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Each vertex v has a threshold
. Each vertex v has a threshold  , and the thresholds
, and the thresholds ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) . At time
. At time  , vertex v become active if
, vertex v become active if  , and if vertex become active at stays active forever. This process ends if no activations occur from round
, and if vertex become active at stays active forever. This process ends if no activations occur from round  to
to  . The influence
. The influence  of a set A of vertices is the expected number of active nodes at the end of the process. The influence maximization problem asks, given graph G, weights
of a set A of vertices is the expected number of active nodes at the end of the process. The influence maximization problem asks, given graph G, weights  , and parameter k, to find a k-vertex set A with maximal
, and parameter k, to find a k-vertex set A with maximal  , there is a polynomial-time algorithm approximating the maximum influence to within a factor of
, there is a polynomial-time algorithm approximating the maximum influence to within a factor of  , where
, where  is the base of the natural logarithm.
is the base of the natural logarithm.