You need to know: Hilbert space  , Banach space B, notation
, Banach space B, notation  for norm in B, convergence in this norm, isomorphic Banach spaces, dimension of a Banach space, finite and infinite dimensional Banach spaces, subspace of a Banach space, bounded linear operator K between Banach spaces, range of K, compact set in a Banach space.
for norm in B, convergence in this norm, isomorphic Banach spaces, dimension of a Banach space, finite and infinite dimensional Banach spaces, subspace of a Banach space, bounded linear operator K between Banach spaces, range of K, compact set in a Banach space.
Background: A sequence 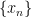 of a Banach space B is called basis of B if every
of a Banach space B is called basis of B if every  has a unique representation of the form
has a unique representation of the form  for some real numbers
for some real numbers 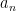 . Two bases and
. Two bases and  of B are called equivalent if series converges in B if and only if
of B are called equivalent if series converges in B if and only if  converges. A basis of B is called symmetric if every permutation of is a basis of B equivalent to .
converges. A basis of B is called symmetric if every permutation of is a basis of B equivalent to .
A Banach space B is said to have the approximation property (AP) if for every compact set K in B and for every  , there is a bounded linear operator
, there is a bounded linear operator  , whose range is finite-dimensional, and such that
, whose range is finite-dimensional, and such that  for all
for all 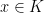 . We say that Banach space B has the hereditary AP (or is a HAPpy space) if all of its subspaces have the AP.
. We say that Banach space B has the hereditary AP (or is a HAPpy space) if all of its subspaces have the AP.
The Theorem: On 7th November 2010, William Johnson and Andrzej Szankowski submitted to the Annals of Mathematics a paper in which they proved the existence of a HAPpy Banach space, not isomorphic to the Hilbert space , which has a symmetric basis.
Short context: The first examples of HAPpy Banach spaces not isomorphic to a Hilbert space was constructed by Johnson in 1980. Later, Pisier constructed more such examples, but none of them have a symmetric basis. In fact, Johnson asked in 1980 whether there exists any HAPpy space, other than , that has a symmetric basis. The Theorem answers this question affirmatively.
Links: The original paper is available here.
Go to the list of all theorems
 , let
, let  be the cardinality of the largest subset of
be the cardinality of the largest subset of  which contains no nontrivial 3-term arithmetic progressions.
which contains no nontrivial 3-term arithmetic progressions. .
. . In 1953, Roth confirmed this conjecture by proving that
. In 1953, Roth confirmed this conjecture by proving that  . In 1999, Bourgain improved this to
. In 1999, Bourgain improved this to  . The Theorem proves a much stronger upper bound, the first one in the form
. The Theorem proves a much stronger upper bound, the first one in the form  . In a later work, Bloom improved the bound slightly to
. In a later work, Bloom improved the bound slightly to  .
.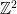 , origin
, origin  , basic probability theory, simple random walk on
, basic probability theory, simple random walk on  be the largest integer not exceeding t.
be the largest integer not exceeding t. , construct a random set
, construct a random set  such that (i)
such that (i)  , and (ii) for each
, and (ii) for each  be
be 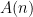 plus the first point at which a simple random walk from the origin hits
plus the first point at which a simple random walk from the origin hits  . For any real
. For any real  , let
, let  . For
. For 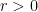 , let
, let  .
. for all sufficiently large r.
for all sufficiently large r.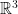 , Euclidean distance in
, Euclidean distance in 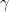 in
in  and
and  are equivalent if
are equivalent if  . The distortion of knot representative
. The distortion of knot representative  , where
, where  denotes the arclength along
denotes the arclength along  denotes the Euclidean distance in
denotes the Euclidean distance in  .
.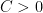 there exists a knot K in
there exists a knot K in  .
. . The Theorem shows that this is not the case, with any constant in place of
. The Theorem shows that this is not the case, with any constant in place of 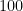 . In fact, Pardon presented explicit examples of families of knots with distortion going to infinity. For example, let
. In fact, Pardon presented explicit examples of families of knots with distortion going to infinity. For example, let  be the curve in
be the curve in  ,
,  ,
,  , where
, where  and
and  . Set
. Set  of curves equivalent to
of curves equivalent to 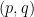 -torus knot. Pardon proved that
-torus knot. Pardon proved that  . The Theorem follows.
. The Theorem follows.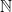 for the set of positive integers, Euclidean space
for the set of positive integers, Euclidean space 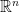 , sphere in
, sphere in  , integration over
, integration over  be a sphere in
be a sphere in  normalised such that
normalised such that  . A set of points
. A set of points  is called a spherical t-design if equality
is called a spherical t-design if equality  holds for all polynomials P in
holds for all polynomials P in  variables, of total degree at most t.
variables, of total degree at most t. there exist a constant
there exist a constant  such that for each
such that for each  and each
and each  , there exists a spherical t-design in
, there exists a spherical t-design in  . In 1993, Korevaar and Meyers conjectured the existence of spherical t-designs in
. In 1993, Korevaar and Meyers conjectured the existence of spherical t-designs in  points, which is optimal up to the constant factor. The Theorem confirms this conjecture.
points, which is optimal up to the constant factor. The Theorem confirms this conjecture. any function
any function  such that
such that  . Let
. Let 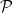 denote the set of all prime numbers.
denote the set of all prime numbers. , the number of k-tuples of primes
, the number of k-tuples of primes  which lie in arithmetic progression is
which lie in arithmetic progression is 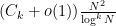 , with
, with  , where
, where  if
if  and
and  if
if  .
.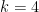 and also proved that the general case (and in fact much more general theorem called “The generalised Hardy-Littlewood conjecture in finite complexity case”) would follow from two new conjectures they formulated. They then, together with Ziegler, proved these conjectures, which finishes the proof of the Theorem.
and also proved that the general case (and in fact much more general theorem called “The generalised Hardy-Littlewood conjecture in finite complexity case”) would follow from two new conjectures they formulated. They then, together with Ziegler, proved these conjectures, which finishes the proof of the Theorem. of real numbers is called log-concave if
of real numbers is called log-concave if  for all
for all  . For a finite graph G and integer
. For a finite graph G and integer  , let
, let  be the number of proper colouring of vertices of G with q colours. It is known that
be the number of proper colouring of vertices of G with q colours. It is known that  , where
, where  are non-negative integers.
are non-negative integers. for some
for some  ). In 1971, Rota conjectured that this sequence is in fact log-concave and observed that this would imply the Read’s conjecture. The Theorem confirms this prediction. In fact, Rota conjectured an even more general statement, which was also
). In 1971, Rota conjectured that this sequence is in fact log-concave and observed that this would imply the Read’s conjecture. The Theorem confirms this prediction. In fact, Rota conjectured an even more general statement, which was also  let
let  denote the greatest prime factor of
denote the greatest prime factor of  when
when  ,
, 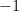 .
.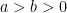 there is a constant
there is a constant  , such that
, such that  for all
for all  .
. for any integers
for any integers 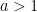 and
and 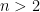 . Can this lower bound be improved? In 1965, Erdős conjectured that
. Can this lower bound be improved? In 1965, Erdős conjectured that  as
as 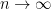 . The Theorem (with
. The Theorem (with  ) proves Erdős conjecture (for any
) proves Erdős conjecture (for any  ) and gives the first improvement on Bang’s bound for 124 years. For general
) and gives the first improvement on Bang’s bound for 124 years. For general  for
for  for large n. The Theorem provides a much better lower bound than
for large n. The Theorem provides a much better lower bound than 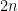 . In fact, Stewart proved, much more generally, that the same lower bound holds for
. In fact, Stewart proved, much more generally, that the same lower bound holds for  , where
, where 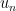 is the n-th term of Lehmer sequence. Previously, it was only known (as a corollary from
is the n-th term of Lehmer sequence. Previously, it was only known (as a corollary from  for
for  .
.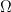 . Let
. Let  be a finite family of events in
be a finite family of events in  , let
, let  be the (unique) minimal subset of
be the (unique) minimal subset of  . For
. For  be the set of
be the set of  such that
such that  but
but  . We say that an evaluation of the variables in
. We say that an evaluation of the variables in  such that
such that ![\forall A\in S: \text{Prob}[A]\leq x(A) \prod\limits_{B\in \Gamma_S(A)} (1-x(B))](https://s0.wp.com/latex.php?latex=%5Cforall+A%5Cin+S%3A+%5Ctext%7BProb%7D%5BA%5D%5Cleq+x%28A%29+%5Cprod%5Climits_%7BB%5Cin+%5CGamma_S%28A%29%7D+%281-x%28B%29%29&bg=ffffff&fg=000000&s=0&c=20201002) , then there exists an assignment of values to the variables in
, then there exists an assignment of values to the variables in  .
. of matrix A.
of matrix A. denote the eigenvalues of
denote the eigenvalues of 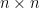 symmetric matrix A. If all
symmetric matrix A. If all  are non-negative, A is called positive semidefinite, while if all
are non-negative, A is called positive semidefinite, while if all  be the set of all positive definite
be the set of all positive definite  , we write
, we write  if
if  is positive semidefinite. The trace metric distance between
is positive semidefinite. The trace metric distance between  . The least squares mean (also known as Karcher mean) of k matrices
. The least squares mean (also known as Karcher mean) of k matrices  is
is  .
. ,
,  , then
, then  .
.