You need to know: Euclidean space 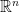 , norm
, norm  of
of  , real matrix L (matrix with real entries
, real matrix L (matrix with real entries  ), matrix multiplication, square matrix, l1 norm
), matrix multiplication, square matrix, l1 norm  of matrix L, support set of L (set of pairs
of matrix L, support set of L (set of pairs 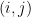 such that
such that  ), diagonal matrix D, identity matrix I, transpose
), diagonal matrix D, identity matrix I, transpose  of matrix L, orthonormal matrix (such that
of matrix L, orthonormal matrix (such that  ) singular value decomposition of a square matrix L (writing
) singular value decomposition of a square matrix L (writing  where D is the diagonal matrix and
where D is the diagonal matrix and  are orthonormal matrices), rank of the matrix L (the number of non-zero entries of D), nuclear norm
are orthonormal matrices), rank of the matrix L (the number of non-zero entries of D), nuclear norm  of L (sum of all entries of D).
of L (sum of all entries of D).
Background: Let  be a fixed real number. Let
be a fixed real number. Let  be a vector with
be a vector with  -th component
-th component  and others
and others  . Let
. Let 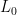 be a real
be a real 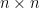 matrix of rank r whose singular value decomposition
matrix of rank r whose singular value decomposition  satisfies (i)
satisfies (i)  , (ii)
, (ii)  , and (iii)
, and (iii)  , where
, where 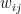 are entries of matrix
are entries of matrix  . Let
. Let  be a fixed
be a fixed 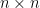 matrix with
matrix with 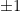 entries
entries  . Choose integer
. Choose integer  . Let
. Let 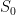 be matrix with entries
be matrix with entries ![[S_0]_{ij}](https://s0.wp.com/latex.php?latex=%5BS_0%5D_%7Bij%7D&bg=ffffff&fg=000000&s=0&c=20201002) whose support set
whose support set 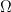 is uniformly distributed among all sets of cardinality m, and such that the sign of is for all
is uniformly distributed among all sets of cardinality m, and such that the sign of is for all  . Let
. Let  . Let
. Let 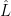 ,
,  be the solution to optimization problem
be the solution to optimization problem  subject to
subject to  .
.
The Theorem: On 18th December 2009, Emmanuel Candes, Xiaodong Li, Yi Ma, and John Wright submitted to arxiv a paper in which they proved the following result. Suppose that and are as above. Then, there are positive constants  ,
,  ,
,  such that with probability at least
such that with probability at least  (over the choice of support of ), we have
(over the choice of support of ), we have  and
and  provided that
provided that  and
and  .
.
Short context: Many real life data has the form of matrix , where is a low-rank matrix and is some perturbation. A fundamental problem, known as “principal component analysis” is to recover from M. Most known method works if is small, but this assumption often fails in applications. The Theorem states that can be efficiently recovered if is sparse, that is, has not too many non-zero entries (which, however, can be arbitrary large!). Conditions (i)-(iii) for are needed to ensure that is not sparse. The Theorem can be extended to rectangular matrices  as well.
as well.
Links: Free arxiv version of the original paper is here, journal version is here.
Go to the list of all theorems










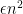




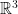 , volume in
, volume in  with center O and radius r, regular tetrahedron.
with center O and radius r, regular tetrahedron. , denote
, denote  where
where 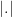 denotes volume in
denotes volume in  .
. . In just few years after this, many author developed denser and denser packings, culminated in the Theorem, which provides the densest packing currently known.
. In just few years after this, many author developed denser and denser packings, culminated in the Theorem, which provides the densest packing currently known. for the set of integers,
for the set of integers, 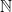 for the set of positive integers, matrix, determinant of a matrix, group, group
for the set of positive integers, matrix, determinant of a matrix, group, group 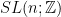 of
of  where S is a set of generators and R is a set of relations, finitely presented group.
where S is a set of generators and R is a set of relations, finitely presented group. , we write
, we write  if there is a c such that
if there is a c such that  for all n, and
for all n, and  if
if  , where the maximum is taken over words of length at most n representing the identity. We say that the Dehn function is quadratic if
, where the maximum is taken over words of length at most n representing the identity. We say that the Dehn function is quadratic if  . This property depends only on G but not on set of generators.
. This property depends only on G but not on set of generators.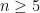 , the Dehn function of
, the Dehn function of 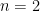 , and exponentially fast for
, and exponentially fast for 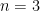 . For
. For  , Thurston conjectured that it grows quadratically. The Theorem confirms this conjecture for
, Thurston conjectured that it grows quadratically. The Theorem confirms this conjecture for 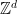 of vectors
of vectors  with integer components,
with integer components,  , origin
, origin  , graph, path in a graph, infinite graph, probability, independence.
, graph, path in a graph, infinite graph, probability, independence. are connected by an edge if and only if
are connected by an edge if and only if  . Given
. Given ![p\in[0,1]](https://s0.wp.com/latex.php?latex=p%5Cin%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) , a bond percolation
, a bond percolation  in
in 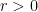 , let
, let  be the probability that there exists a path in
be the probability that there exists a path in  with
with  . It is known that for every
. It is known that for every 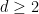 there exists a
there exists a ![p_d \in [0,1]](https://s0.wp.com/latex.php?latex=p_d+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) such that
such that  for
for  but
but  for
for  .
. for every
for every 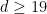 , where
, where  means that
means that  for some constant
for some constant 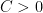 which might depend on d but not on r.
which might depend on d but not on r. . It is believed that
. It is believed that  for all
for all  for some
for some  , which is called the one-arm exponent for critical bond percolation in
, which is called the one-arm exponent for critical bond percolation in  .
. , big O notation.
, big O notation.![[k]=\{1,2,\dots,k\}](https://s0.wp.com/latex.php?latex=%5Bk%5D%3D%5C%7B1%2C2%2C%5Cdots%2Ck%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002) and let
and let ![[k]^n](https://s0.wp.com/latex.php?latex=%5Bk%5D%5En&bg=ffffff&fg=000000&s=0&c=20201002) be the set of vectors
be the set of vectors  such that each
such that each ![x_i\in[k]](https://s0.wp.com/latex.php?latex=x_i%5Cin%5Bk%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Let
. Let  be a vector such that each
be a vector such that each 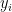 either belongs to
either belongs to ![[k]](https://s0.wp.com/latex.php?latex=%5Bk%5D&bg=ffffff&fg=000000&s=0&c=20201002) or equal to the wildcard value *. Assume that at least one coordinate of y takes the wildcard value *. For
or equal to the wildcard value *. Assume that at least one coordinate of y takes the wildcard value *. For  , let
, let ![y^j \in [k]^n](https://s0.wp.com/latex.php?latex=y%5Ej+%5Cin+%5Bk%5D%5En&bg=ffffff&fg=000000&s=0&c=20201002) be a vector obtained from y by setting all the wildcards * equal to j. The set
be a vector obtained from y by setting all the wildcards * equal to j. The set  is called a combinatorial line. Let
is called a combinatorial line. Let  be a function such that
be a function such that  for all k,
for all k,  for all n, and
for all n, and  for all
for all  .
. , there exists a positive integer
, there exists a positive integer  such that if
such that if  and A is any subset of
and A is any subset of  elements, then A contains a combinatorial line. Moreover, one may take
elements, then A contains a combinatorial line. Moreover, one may take  and
and  for
for  .
. and any
and any  , there exists a positive integer
, there exists a positive integer  such that every subset of the set
such that every subset of the set  of size at least
of size at least  contains an arithmetic progression of length k. In 1991, Furstenberg and Katznelson proved the statement of the Theorem without “moreover” part, and called it “the density Hales-Jewett theorem”. This theorem greatly generalises (and easily implies) the Szemerédi theorem. However, the proof of Furstenberg and Katznelson does not imply any explicit algorithm how to actually compute
contains an arithmetic progression of length k. In 1991, Furstenberg and Katznelson proved the statement of the Theorem without “moreover” part, and called it “the density Hales-Jewett theorem”. This theorem greatly generalises (and easily implies) the Szemerédi theorem. However, the proof of Furstenberg and Katznelson does not imply any explicit algorithm how to actually compute  and
and 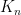 for complete graph on n vertices, notations
for complete graph on n vertices, notations  and
and  for the number of vertices and edges in graph H, respectively.
for the number of vertices and edges in graph H, respectively.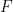 with
with  and
and  , let
, let  be the maximum value of
be the maximum value of  over all subgraphs H of F with
over all subgraphs H of F with  . We say that a graph is F-free if it does not contain a copy of a graph F as a subgraph. For graph G, we write
. We say that a graph is F-free if it does not contain a copy of a graph F as a subgraph. For graph G, we write  for the maximal number of edges that an F-free subgraph of G may have. Number
for the maximal number of edges that an F-free subgraph of G may have. Number  is known as Turán density of graph F. The Erdős-Renyi graph
is known as Turán density of graph F. The Erdős-Renyi graph  is a random graph with n vertices, such that every possible edge is included independently with probability
is a random graph with n vertices, such that every possible edge is included independently with probability  .
. such that for every sequence of probabilities
such that for every sequence of probabilities  , we have
, we have ![\lim\limits_{n\to\infty} P\left[\text{ex}(G(n,q_n),F) \leq \left(\pi(F)+\epsilon\right)e(G(n,q_n))\right]=1](https://s0.wp.com/latex.php?latex=%5Clim%5Climits_%7Bn%5Cto%5Cinfty%7D+P%5Cleft%5B%5Ctext%7Bex%7D%28G%28n%2Cq_n%29%2CF%29+%5Cleq+%5Cleft%28%5Cpi%28F%29%2B%5Cepsilon%5Cright%29e%28G%28n%2Cq_n%29%29%5Cright%5D%3D1&bg=ffffff&fg=000000&s=0&c=20201002) .
. for all integers n and k. For general graph G, it is known that
for all integers n and k. For general graph G, it is known that  . The Theorem proves that if G is a random graph, then the opposite inequality
. The Theorem proves that if G is a random graph, then the opposite inequality  holds with high probability. It confirms a conjecture of Kohayakawa, Łuczak, and Roedl made in 1997.
holds with high probability. It confirms a conjecture of Kohayakawa, Łuczak, and Roedl made in 1997.![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) , multiplication of a set by a constant
, multiplication of a set by a constant  , sum of two sets
, sum of two sets  , Hausdorff dimension
, Hausdorff dimension  of set
of set ![A \subset [0,1]](https://s0.wp.com/latex.php?latex=A+%5Csubset+%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
. , let
, let  be the largest integer not exceeding x, and let
be the largest integer not exceeding x, and let  . For integer m, let
. For integer m, let  be a function given by
be a function given by  . We say that set
. We say that set ![S \subset [0,1]](https://s0.wp.com/latex.php?latex=S+%5Csubset+%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) is invariant under
is invariant under  if
if  for every
for every  .
.![X; Y \subseteq [0,1]](https://s0.wp.com/latex.php?latex=X%3B+Y+%5Csubseteq+%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) be closed sets which are invariant under
be closed sets which are invariant under 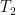 and
and  , respectively. Then, for any
, respectively. Then, for any  ,
,  .
. , small o notation.
, small o notation. moves, for every
moves, for every  , for all large enough n.
, for all large enough n. (in 2009, Hefetz and Stich proved that Maker can win in just n+1 rounds, which is optimal). In general, the critical bias
(in 2009, Hefetz and Stich proved that Maker can win in just n+1 rounds, which is optimal). In general, the critical bias  is the maximum possible value of b for which Maker still wins the (1 : b) game played on
is the maximum possible value of b for which Maker still wins the (1 : b) game played on  . Many authors proved better and better lower bounds, culminating in the Theorem which implies that
. Many authors proved better and better lower bounds, culminating in the Theorem which implies that  , and hence equality holds.
, and hence equality holds. for set of vectors
for set of vectors  with complex
with complex 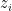 , algorithm, probabilistic and deterministic algorithms, average running time of an algorithm, big O notation.
, algorithm, probabilistic and deterministic algorithms, average running time of an algorithm, big O notation. be a positive integer. Let H be the space of all systems
be a positive integer. Let H be the space of all systems ![f = [f_1,\dots ,f_n]:{\mathbb C}^n \to {\mathbb C}^n](https://s0.wp.com/latex.php?latex=f+%3D+%5Bf_1%2C%5Cdots+%2Cf_n%5D%3A%7B%5Cmathbb+C%7D%5En+%5Cto+%7B%5Cmathbb+C%7D%5En&bg=ffffff&fg=000000&s=0&c=20201002) on n polynomial equations in n unknowns. For
on n polynomial equations in n unknowns. For  , denote
, denote  the set of solutions of
the set of solutions of  .
.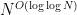 , where N is the size of the input.
, where N is the size of the input. , see
, see 