You need to know: Euclidean space 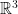 , rotation in , rigid motion in , surface in , surface area, neighbourhood of a point in the surface, boundary, surface with and without self-intersections, compact subset of , compact subset of a surface, connected surface.
, rotation in , rigid motion in , surface in , surface area, neighbourhood of a point in the surface, boundary, surface with and without self-intersections, compact subset of , compact subset of a surface, connected surface.
Background: A surface  is called a minimal surface if every point
is called a minimal surface if every point 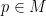 has a neighbourhood S, with boundary B, such that S has a minimal area out of all surfaces S’ with the same boundary B. A surface is called properly embedded in , if it has no boundary, no self-intersections, and its intersection with any compact subset of is compact. We say that surface has genus
has a neighbourhood S, with boundary B, such that S has a minimal area out of all surfaces S’ with the same boundary B. A surface is called properly embedded in , if it has no boundary, no self-intersections, and its intersection with any compact subset of is compact. We say that surface has genus  if cutting it along any closed curve makes it disconnected. A planar domain is a connected surface that is noncompact and has genus .
if cutting it along any closed curve makes it disconnected. A planar domain is a connected surface that is noncompact and has genus .
The Theorem: On 8th November 2007, William Meeks III, Joaquin Perez, and Antonio Ros submitted to Annals of Mathematics a paper in which they proved that any connected properly embedded minimal planar domain M in can be rotated such that, after rotation, it intersects every horizontal plane in a circle or in a line.
Short context: Minimal surfaces, ones that locally minimizes their areas, are among the most studied objects in geometry and topology. A trivial example of minimal surface is the plain. One of the simplest non-trivial examples, described by Euler in 1774, is a helicoid, see here. There are other examples like catenoid and one-parameter family  of Riemann minimal examples. We will not define these surfaces here but mention that the main result in the paper of Meeks, Perez, and Ros is that, up to scaling and rigid motion, any connected properly embedded minimal planar domain M in must be one of the examples listed above! Because the concusion of the Theorem was known to hold in all these examples, the Theorem follows.
of Riemann minimal examples. We will not define these surfaces here but mention that the main result in the paper of Meeks, Perez, and Ros is that, up to scaling and rigid motion, any connected properly embedded minimal planar domain M in must be one of the examples listed above! Because the concusion of the Theorem was known to hold in all these examples, the Theorem follows.
Links: Free arxiv version of the original paper is here, journal version is here.
Go to the list of all theorems
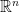













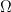



 , integration in
, integration in  , notation
, notation  for the volume (Lebesgue measure) of set
for the volume (Lebesgue measure) of set  .
. , denote
, denote  . For
. For  and
and 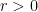 , let
, let  . Let
. Let  be the set of all functions
be the set of all functions  such that
such that  . For any
. For any  , let
, let  . Let
. Let  be the lowest constant
be the lowest constant  such that inequality
such that inequality  holds for all
holds for all  .
. .
. and that
and that  for all d (note that
for all d (note that  for all d).
for all d). for probability, random variable, distribution.
for probability, random variable, distribution. be assigned independent random cost
be assigned independent random cost  from a fixed distribution
from a fixed distribution  on the non-negative real numbers, such that
on the non-negative real numbers, such that  . Let
. Let  be the minimum sum of the edge costs of a cycle that visits each vertex precisely once. For any
be the minimum sum of the edge costs of a cycle that visits each vertex precisely once. For any 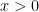 , let
, let  be the unique real number such that
be the unique real number such that  . Let
. Let  .
. ,
, ![\lim\limits_{n\to \infty}P\left[\left|L_n - L^*\right|>\epsilon\right] = 0.](https://s0.wp.com/latex.php?latex=%5Clim%5Climits_%7Bn%5Cto+%5Cinfty%7DP%5Cleft%5B%5Cleft%7CL_n+-+L%5E%2A%5Cright%7C%3E%5Cepsilon%5Cright%5D+%3D+0.&bg=ffffff&fg=000000&s=0&c=20201002)
![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002) or exponential with mean
or exponential with mean  .
.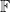 be a finite field with
be a finite field with  elements, and let
elements, and let  be a vector space over
be a vector space over  such that for every
such that for every  there exists a point
there exists a point  such that the set
such that the set  (called a line) is contained in K.
(called a line) is contained in K. , where
, where  is a constant that depends only on
is a constant that depends only on  .
. , which contains a line segment of unit length in every direction, must have Hausdorff dimension equal to n. This conjecture has connections to problems in number theory, harmonic analysis, and the analysis of partial differential equations, but remains open for all
, which contains a line segment of unit length in every direction, must have Hausdorff dimension equal to n. This conjecture has connections to problems in number theory, harmonic analysis, and the analysis of partial differential equations, but remains open for all 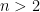 . In 1999, Wolff suggested to study its finite field analogue. The Theorem resolves the Kakeya conjecture is finite fields.
. In 1999, Wolff suggested to study its finite field analogue. The Theorem resolves the Kakeya conjecture is finite fields. (function in n variables), partial derivatives of such function, differential equation.
(function in n variables), partial derivatives of such function, differential equation. for some constant
for some constant  . For a twice-differentiable function
. For a twice-differentiable function  is
is  .
. , there exists a solution
, there exists a solution 
 ; (ii)
; (ii)  for every
for every  ; but (iii) the level sets of u are not hyperplanes.
; but (iii) the level sets of u are not hyperplanes.  . This conjecture, when true, allows to write down a formula for u easily. It is known to hold in dimensions
. This conjecture, when true, allows to write down a formula for u easily. It is known to hold in dimensions  , and, under some additional conditions, in all dimensions
, and, under some additional conditions, in all dimensions  .
. is the unique function which has properties (i)
is the unique function which has properties (i)  if
if  and (ii)
and (ii)  if
if 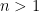 .
.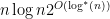 for n-digit integers.
for n-digit integers. operations for n-digit integers. In 1971, Schönhage and Strassen presented a much faster
operations for n-digit integers. In 1971, Schönhage and Strassen presented a much faster  algorithm, and conjectured that
algorithm, and conjectured that 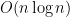 algorithm should exist. This algorithm remained the fastest one for 36 years. The Theorem presents a faster method whose running time is very close to
algorithm should exist. This algorithm remained the fastest one for 36 years. The Theorem presents a faster method whose running time is very close to  factor and presented the
factor and presented the  of
of  , convex set
, convex set  , convex function on D, probability measure
, convex function on D, probability measure  such that
such that  for every measurable
for every measurable  . If set
. If set  is convex, and
is convex, and  is a convex function on D, then
is a convex function on D, then  , we write
, we write  , and
, and  . Function f is called 1-Lipschitz if
. Function f is called 1-Lipschitz if  for all
for all  . We say that
. We say that  such that for every 1-Lipschitz f we have
such that for every 1-Lipschitz f we have  .
. holds for all
holds for all 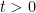 , where c and C are universal constants.
, where c and C are universal constants. is also random and unpredictable. However, if the conclusion of the theorem (known as exponential concentration) holds, then
is also random and unpredictable. However, if the conclusion of the theorem (known as exponential concentration) holds, then  with very high probability. This property looks much stronger than “just” first moment concentration. The Theorem states, however, that these concentrations are in fact equivalent! In fact, in the same paper authors studied several other notions of concentrations, some looks very week and some very strong, and proved that they are all equivalent for the log-concave
with very high probability. This property looks much stronger than “just” first moment concentration. The Theorem states, however, that these concentrations are in fact equivalent! In fact, in the same paper authors studied several other notions of concentrations, some looks very week and some very strong, and proved that they are all equivalent for the log-concave  of complex number z, function of complex variable, meromorphic function, analytic continuation.
of complex number z, function of complex variable, meromorphic function, analytic continuation. with
with  , let
, let  . By analytic continuation, function
. By analytic continuation, function  can be extended to a meromorphic function on the whole complex plane, and it is called the Riemann zeta function.
can be extended to a meromorphic function on the whole complex plane, and it is called the Riemann zeta function. , there is an effectively computable constant
, there is an effectively computable constant  and absolute constant k, such that for any
and absolute constant k, such that for any  the value of
the value of 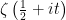 can be computed to within
can be computed to within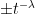 using at most
using at most  operations.
operations. is one of the most studied functions in mathematics, and is central to, for example, understanding the distribution of prime numbers. The values
is one of the most studied functions in mathematics, and is central to, for example, understanding the distribution of prime numbers. The values  are particularly important. Before 2007, the fastest algorithm to approximately compute
are particularly important. Before 2007, the fastest algorithm to approximately compute  . The Theorem improves the exponent to
. The Theorem improves the exponent to  .
. .
.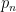 denotes the n-th prime number.
denotes the n-th prime number. .
. for infinitely many n, and is wide open. In an
for infinitely many n, and is wide open. In an  , that is, there exist consecutive primes which are closer than
, that is, there exist consecutive primes which are closer than  for any
for any  . Using methods developed in these papers, Zhang
. Using methods developed in these papers, Zhang  infinitely often. This result was then improved to
infinitely often. This result was then improved to  .
.