You need to know: Set  of integers, probability, independent random variables, exponential distribution, expectation, variance. For
of integers, probability, independent random variables, exponential distribution, expectation, variance. For  , denote
, denote ![[x]](https://s0.wp.com/latex.php?latex=%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002) the largest integer in
the largest integer in ![[0, x]](https://s0.wp.com/latex.php?latex=%5B0%2C+x%5D&bg=ffffff&fg=000000&s=0&c=20201002) if
if  , and the smallest integer in
, and the smallest integer in ![[x, 0]](https://s0.wp.com/latex.php?latex=%5Bx%2C+0%5D&bg=ffffff&fg=000000&s=0&c=20201002) if
if 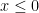 .
.
Background: At time 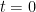 , let us put, for each
, let us put, for each  , a particle in site x, independently and with the same probability
, a particle in site x, independently and with the same probability  . Then, for each particle z, independently generate a random variable
. Then, for each particle z, independently generate a random variable  from exponential distribution with parameter 1, wait for time , and then jump to an adjacent site right or left, with probabilities
from exponential distribution with parameter 1, wait for time , and then jump to an adjacent site right or left, with probabilities  and
and 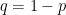 , respectively, provided that the target site is unoccupied (and otherwise stay). This action is then repeated and performed in parallel for all particles. We call this asymmetric simple exclusion process (ASEP). For
, respectively, provided that the target site is unoccupied (and otherwise stay). This action is then repeated and performed in parallel for all particles. We call this asymmetric simple exclusion process (ASEP). For  , let
, let  , where
, where  is the number of particles that began in
is the number of particles that began in ![(-\infty,0]](https://s0.wp.com/latex.php?latex=%28-%5Cinfty%2C0%5D&bg=ffffff&fg=000000&s=0&c=20201002) at time
at time  but lie in
but lie in ![[[vt]+1,\infty)](https://s0.wp.com/latex.php?latex=%5B%5Bvt%5D%2B1%2C%5Cinfty%29&bg=ffffff&fg=000000&s=0&c=20201002) at time t, and
at time t, and  is the number of particles that began in
is the number of particles that began in  at time but lie in
at time but lie in ![(-\infty,[vt]]](https://s0.wp.com/latex.php?latex=%28-%5Cinfty%2C%5Bvt%5D%5D&bg=ffffff&fg=000000&s=0&c=20201002) at time t.
at time t.
The Theorem: On 15st August 2006, Márton Balázs and Timo Seppäläinen submitted to arxiv a paper in which they proved that, for  , there exists positive constants
, there exists positive constants  and
and  , such that
, such that  , for all
, for all  .
.
Short context: ASEP is one of the simplest models for diffusion processes – see here for its the 2-dimensional version. Random variable  has the meaning of the total net particle current seen by an observer moving at speed v during time interval
has the meaning of the total net particle current seen by an observer moving at speed v during time interval ![[0,t]](https://s0.wp.com/latex.php?latex=%5B0%2Ct%5D&bg=ffffff&fg=000000&s=0&c=20201002) . In 1994, Ferrari and Fontes proved that
. In 1994, Ferrari and Fontes proved that  , which implies that the variance grows linearly in time, except when , which is called the characteristic speed. for this v is called the current across the characteristic, and The Theorem proves that its variance grows as
, which implies that the variance grows linearly in time, except when , which is called the characteristic speed. for this v is called the current across the characteristic, and The Theorem proves that its variance grows as 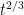 .
.
Links: Free arxiv version of the original paper is here, journal version is here. See also Section 10.5 of this book for an accessible description of the Theorem.
Go to the list of all theorems
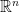 , matrix, transpose
, matrix, transpose  of matrix (or vector) A, symmetric matrix, matrix multiplication, Moore-Penrose inverse
of matrix (or vector) A, symmetric matrix, matrix multiplication, Moore-Penrose inverse  of matrix
of matrix  , randomised algorithm, expected running time, big O notation,
, randomised algorithm, expected running time, big O notation,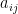 is called weakly diagonally dominant if
is called weakly diagonally dominant if  for all i. For
for all i. For 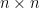 symmetric matrix
symmetric matrix  , the A-norm of x is
, the A-norm of x is  .
. nonzero entries, vector
nonzero entries, vector  , and
, and  , produces an
, produces an  such that
such that  in expected time
in expected time  for some constant
for some constant  .
. ,
,  , be the set of all polynomials in k variables with real coefficients. A polynomial
, be the set of all polynomials in k variables with real coefficients. A polynomial  of degree n is called stable (or hyperbolic) if it has n real roots (counting multiplicity). We say that stable polynomials
of degree n is called stable (or hyperbolic) if it has n real roots (counting multiplicity). We say that stable polynomials  are interlacing if either
are interlacing if either  or
or  , where
, where  and
and  are roots of
are roots of 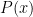 and
and 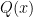 , respectively.
, respectively. is stable if
is stable if  is stable for any real
is stable for any real 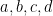 such that
such that  and
and 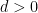 . For a linear operator
. For a linear operator  , let
, let  be a linear operator such that
be a linear operator such that  , for all
, for all  and
and  . We say that linear operator
. We say that linear operator  is a stable polynomial whenever
is a stable polynomial whenever  is stable.
is stable. , where
, where  ,
,  are real numbers, and
are real numbers, and ![S_T[(x+y)^k]\in {\cal P}_2](https://s0.wp.com/latex.php?latex=S_T%5B%28x%2By%29%5Ek%5D%5Cin+%7B%5Ccal+P%7D_2&bg=ffffff&fg=000000&s=0&c=20201002) is a stable polynomial for all
is a stable polynomial for all ![S_T[(x-y)^k]\in {\cal P}_2](https://s0.wp.com/latex.php?latex=S_T%5B%28x-y%29%5Ek%5D%5Cin+%7B%5Ccal+P%7D_2&bg=ffffff&fg=000000&s=0&c=20201002) is a stable polynomial for all
is a stable polynomial for all  , where
, where  is a given sequence of numbers. The Theorem provides a characterization of all stability-preserving operators.
is a given sequence of numbers. The Theorem provides a characterization of all stability-preserving operators. .
.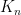 denote the complete graph with n vertices. The (two-colour) Ramsey number
denote the complete graph with n vertices. The (two-colour) Ramsey number  is the smallest natural number n such that, in any red and blue colouring of the edges of
is the smallest natural number n such that, in any red and blue colouring of the edges of  . The Ramsey numbers
. The Ramsey numbers  are called diagonal.
are called diagonal.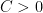 such that inequality
such that inequality  holds for all integers
holds for all integers 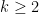 .
. exists n such that any red-blue edge colouring of
exists n such that any red-blue edge colouring of  . In particular,
. In particular,  . In 1988, Thomason improved it to
. In 1988, Thomason improved it to  . The Theorem is a major improvement of the Thomason’s bound. In particular, it implies that for any
. The Theorem is a major improvement of the Thomason’s bound. In particular, it implies that for any  there is a constant
there is a constant  such that
such that  for all k.
for all k. for the number of elements in a finite set S.
for the number of elements in a finite set S. .
. .
. of size at least n/3 that is sum-free, that is, S does not contain integers x, y and z such that
of size at least n/3 that is sum-free, that is, S does not contain integers x, y and z such that  . In 1985, Babai and Sós asked for a generalisation: does every finite group G contain a product-free subset of size
. In 1985, Babai and Sós asked for a generalisation: does every finite group G contain a product-free subset of size  for some
for some 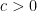 ? As a partial result, they managed to prove the existence of product-free subsets of size
? As a partial result, they managed to prove the existence of product-free subsets of size  , which was improved to
, which was improved to  by Kedlaya in 1997. The Theorem, however, shows that the answer to the Babai and Sós question is no.
by Kedlaya in 1997. The Theorem, however, shows that the answer to the Babai and Sós question is no. , independent and identically distributed (i.i.d.) random vectors, Gaussian distribution in
, independent and identically distributed (i.i.d.) random vectors, Gaussian distribution in  be a random point cloud consisting of
be a random point cloud consisting of  points
points  , sampled independently and identically from a Gaussian distribution in
, sampled independently and identically from a Gaussian distribution in  , each subset of
, each subset of  can be separated from other points of
can be separated from other points of  , or
, or  for some
for some  , where
, where  are integer coefficients.
are integer coefficients. over integers in
over integers in  variables, there exists integers
variables, there exists integers  , not all zero, such that
, not all zero, such that  .
. is indefinite if it is less than
is indefinite if it is less than 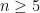 variables has a non-trivial zero. All cubic forms are indefinite, and it is conjectured that they must have a non-trivial zero if
variables has a non-trivial zero. All cubic forms are indefinite, and it is conjectured that they must have a non-trivial zero if  . In 1963, Davenport proved this for
. In 1963, Davenport proved this for  . After more then 40 years with no further progress, the Theorem proves this for
. After more then 40 years with no further progress, the Theorem proves this for  any function
any function  such that
such that  .
. which lie in arithmetic progression is
which lie in arithmetic progression is  , with
, with  , where the product is over all primes
, where the product is over all primes  .
. such progressions consisting of primes at most N, where
such progressions consisting of primes at most N, where  are some small constants. The Theorem provides the exact asymptotic count of the 4-term progressions. Moreover, the authors formulated conjectures which imply the exact count of the k-term progressions for all k, and much more. They then proved these conjectures in later works.
are some small constants. The Theorem provides the exact asymptotic count of the 4-term progressions. Moreover, the authors formulated conjectures which imply the exact count of the k-term progressions for all k, and much more. They then proved these conjectures in later works.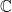 of complex numbers, absolute value
of complex numbers, absolute value 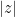 of complex number z, boundary of a set, area (that is, Lebesgue measure) of a set
of complex number z, boundary of a set, area (that is, Lebesgue measure) of a set  , the notion of (Lebesgue) almost all.
, the notion of (Lebesgue) almost all. , let
, let  be the set of points
be the set of points  such that the sequence
such that the sequence  is bounded, that is,
is bounded, that is,  for some
for some  . The boundary
. The boundary  of
of  is called the Julia set of f.
is called the Julia set of f. such that an arbitrarily small perturbation can cause significant changes in the sequence of iterated function values. The Julia set is known to have zero area for many families of quadratic polynomials, including a family which contains
such that an arbitrarily small perturbation can cause significant changes in the sequence of iterated function values. The Julia set is known to have zero area for many families of quadratic polynomials, including a family which contains  in
in  with a non-empty interior.
with a non-empty interior. converging to
converging to  in
in  , and
, and  such that
such that  where
where  .
. of
of  is close to a normal distribution if n is large. Moreover, the same is true for
is close to a normal distribution if n is large. Moreover, the same is true for  , under some mild conditions on unit vector
, under some mild conditions on unit vector  may be far from being independent.
may be far from being independent.