You need to know: Boolean algebra of sets.
Background: Let 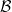











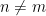







The Theorem: On 27th January 2006, Michel Talagrand submitted to arxiv a paper in which he proved the existence of a Boolean algebra
Short context: Any measure is exhaustive. Moreover, if a submeasure is absolutely continuous with respect to a measure, it is exhaustive. One of the many equivalent formulations of famous Maharam’s problem is whether the converse is true. The Theorem gives a negative answer to this question.
Links: Free arxiv version of the original paper is here, journal version is here. See also Section 8.13 of this book for an accessible description of the Theorem.
 for the number of elements in a finite group G, simple group, free group.
for the number of elements in a finite group G, simple group, free group. be a non-trivial group word, that is, a non-identity element of the free group
be a non-trivial group word, that is, a non-identity element of the free group  on
on  . For a group G, denote
. For a group G, denote  the set of all elements
the set of all elements 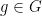 which can be obtained by substitution of some
which can be obtained by substitution of some  into w instead of
into w instead of  , respectively, and performing the group operation. For subsets
, respectively, and performing the group operation. For subsets  of group G, let
of group G, let  . Denote
. Denote  .
. such that for every finite simple group G with
such that for every finite simple group G with  we have
we have 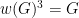 .
. such that
such that  for every large finite simple group G? This was proved for the commutator word
for every large finite simple group G? This was proved for the commutator word  by Wilson in 1994, and for the power word
by Wilson in 1994, and for the power word  by Martinez and Zelmanov in 1996.
by Martinez and Zelmanov in 1996.  , independently of w.
, independently of w.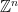 for the set of vectors
for the set of vectors  with integer
with integer  .
. is a polynomial family with k parameters if there are exist n polynomials
is a polynomial family with k parameters if there are exist n polynomials  in k variables with integer coefficients such that
in k variables with integer coefficients such that  such that
such that  .
. is a polynomial family with 46 parameters.
is a polynomial family with 46 parameters.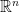 , inner product
, inner product  in
in  , integration in
, integration in  , convex body in
, convex body in  is called isotropic if it has volume 1, its centre of mass is at the origin, and there exists a positive constant
is called isotropic if it has volume 1, its centre of mass is at the origin, and there exists a positive constant  such that
such that  for every
for every  .
.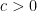 such that if x is selected uniformly at random inside an isotropic convex body K in
such that if x is selected uniformly at random inside an isotropic convex body K in  for every
for every  .
.![L_K \leq c \sqrt[4]{n}](https://s0.wp.com/latex.php?latex=L_K+%5Cleq+c+%5Csqrt%5B4%5D%7Bn%7D&bg=ffffff&fg=000000&s=0&c=20201002) for every isotropic convex body K in
for every isotropic convex body K in  for some constant c independent of n.
for some constant c independent of n. for set difference and
for set difference and  for the symmetric difference of sets A and B, Euclidean space
for the symmetric difference of sets A and B, Euclidean space  of a Borel set
of a Borel set  , boundary
, boundary  of
of 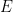 , distributional perimeter
, distributional perimeter  of
of  of a Borel
of a Borel  is
is  , where
, where  is perimeter and B is a ball such that
is perimeter and B is a ball such that  .
.  of a
of a  where
where  is the radius of ball B.
is the radius of ball B. there exists a constant
there exists a constant  such that inequality
such that inequality ![\lambda(E) \leq C_n \sqrt[2]{D(E)}](https://s0.wp.com/latex.php?latex=%5Clambda%28E%29+%5Cleq+C_n+%5Csqrt%5B2%5D%7BD%28E%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) holds for every Borel set
holds for every Borel set  .
. , that is, the perimeter of E may be close to optimal (
, that is, the perimeter of E may be close to optimal (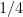 in his inequality can be improved to
in his inequality can be improved to  , and this is optimal. The Theorem confirms this conjecture.
, and this is optimal. The Theorem confirms this conjecture.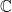 of complex numbers, polynomials in complex variable, root of a polynomial, derivative, notation
of complex numbers, polynomials in complex variable, root of a polynomial, derivative, notation  for j-th derivative of polynomial
for j-th derivative of polynomial  , matrix, determinant of a matrix, vector space, basis of a vector space.
, matrix, determinant of a matrix, vector space, basis of a vector space. be a finite set of polynomials in complex variable z with complex coefficients. The complex span S of
be a finite set of polynomials in complex variable z with complex coefficients. The complex span S of 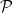 is the set of polynomials
is the set of polynomials  for some
for some  . The Wronskian
. The Wronskian  of
of 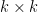 matrix with entries
matrix with entries  .
. .
. be an integer. Any integer
be an integer. Any integer  can be uniquely represented as
can be uniquely represented as  , where
, where  is an integer and
is an integer and  are integers between
are integers between  and
and 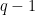 , which are called digits of n in the q-ary number system (if
, which are called digits of n in the q-ary number system (if  , these are the digits in the usual decimal system). Let
, these are the digits in the usual decimal system). Let  be the sum of digits of n. Let
be the sum of digits of n. Let  be the number of primes less than n, and let
be the number of primes less than n, and let  be the number of primes p less than n such that
be the number of primes p less than n such that  is a multiple of m.
is a multiple of m.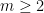 and
and  such that
such that  are relatively prime, there exist constants
are relatively prime, there exist constants  and
and  , such that the inequality
, such that the inequality  holds for all integers
holds for all integers  .
. is known to be negligible comparing to
is known to be negligible comparing to  , that is, the primes whose sum of digits gives any fixed reminder after division by m occupies about
, that is, the primes whose sum of digits gives any fixed reminder after division by m occupies about 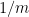 of all primes, as intuitively expected. This answers the 1968 question of Gelfond. In the special case
of all primes, as intuitively expected. This answers the 1968 question of Gelfond. In the special case  , it states that asymptotically half of all primes have the even sum of digits, and half of primes have the odd sum of digits.
, it states that asymptotically half of all primes have the even sum of digits, and half of primes have the odd sum of digits. for length of
for length of  , matrix multiplication, inverse matrix, norm
, matrix multiplication, inverse matrix, norm  of
of 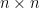 matrix A.
matrix A.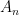 be an
be an 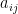 are i.i.d. Bernoulli random variables (taking values
are i.i.d. Bernoulli random variables (taking values 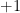 and
and 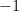 with probability
with probability 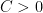 , there are constants B and N such that for any
, there are constants B and N such that for any  the inequality
the inequality  holds with probability at least
holds with probability at least  .
. of its inverse matrix is polynomially bounded with probability at least
of its inverse matrix is polynomially bounded with probability at least  .
. (group of
(group of 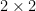 matrices over
matrices over  with determinant 1, see
with determinant 1, see  is the graph whose vertices are elements of G, and vertices
is the graph whose vertices are elements of G, and vertices  are connected by edge if
are connected by edge if  or
or  for some
for some  .
.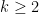 . For any prime
. For any prime  , let
, let  be a
be a  -element subset of
-element subset of  whose elements are chosen independently at random, and let
whose elements are chosen independently at random, and let 

 .
.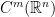 (see
(see  for the norm in this space, algorithm, its running time and memory use.
for the norm in this space, algorithm, its running time and memory use. and
and  be given functions on E. Let
be given functions on E. Let  denote the infimum of all
denote the infimum of all  for which there exists
for which there exists  such that
such that  and
and  for all
for all  . We say that two numbers
. We say that two numbers  determined by
determined by  have the same order of magnitude if
have the same order of magnitude if  , where constants c and C depends only on m and n. By “compute the order of magnitude of X” we mean compute some Y such that X and Y have the same order of magnitude.
, where constants c and C depends only on m and n. By “compute the order of magnitude of X” we mean compute some Y such that X and Y have the same order of magnitude. and using memory at most
and using memory at most  , where the constant C depends only on m and n.
, where the constant C depends only on m and n. ), or approximate one (
), or approximate one ( ). The Theorem proves the existence of efficient algorithm which approximately computes the smallest possible
). The Theorem proves the existence of efficient algorithm which approximately computes the smallest possible 