You need to know: Euclidean space  with scalar product
with scalar product  , norms
, norms  ,
,  , and
, and  in , support of vector
in , support of vector  (subset
(subset  such that
such that 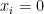 for all
for all  ),
),  matrix, matrix multiplication, notation
matrix, matrix multiplication, notation  for the transpose of matrix
for the transpose of matrix  , big O notation, linear programming, basic probability, mean, variance, independent identically distributed (i.i.d.) random variables, normal distribution
, big O notation, linear programming, basic probability, mean, variance, independent identically distributed (i.i.d.) random variables, normal distribution  with mean
with mean  and variance
and variance  .
.
Background: A vector  is called S-sparse if it is supported on
is called S-sparse if it is supported on  with
with  . For let
. For let  , where A is matrix (
, where A is matrix ( ) and
) and  is a random error (noise) whose components
is a random error (noise) whose components  are i.i.d. and follow
are i.i.d. and follow  . The Dantzig selector
. The Dantzig selector  is a solution to the problem
is a solution to the problem  subject to
subject to  , where
, where  is a constant.
is a constant.
For , let  be
be  submatrix of A formed from the columns of A corresponding to the indices in T. For
submatrix of A formed from the columns of A corresponding to the indices in T. For  , let
, let  be the smallest number such that inequalities
be the smallest number such that inequalities  hold for all T with
hold for all T with  and all
and all  . Also, for
. Also, for  , such that
, such that  , let
, let  be the smallest number such that inequality
be the smallest number such that inequality  holds for all disjoint sets
holds for all disjoint sets  with and
with and  and all ,
and all ,  .
.
The Theorem: On 5th June 2005, Emmanuel Candes and Terence Tao submitted to arxiv a paper in which they proved the following result. Let A be matrix (), S be such that  , be S-sparse, and
, be S-sparse, and  be the Dantzig selector with
be the Dantzig selector with  for some
for some 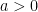 . Then inequality
. Then inequality  , where
, where  , holds with probability exceeding
, holds with probability exceeding  .
.
Short context: In the previous paper, Candes, Romberg, and Tao developed an efficient procedure witch uses the results of a low number ( random measurements suffices) of measurements with arbitrary (random or non-random) error
random measurements suffices) of measurements with arbitrary (random or non-random) error  , to recover S-sparse vector with error
, to recover S-sparse vector with error  . With arbitrary , this result is optimal. The Theorem, however, states that with random measurement error (which often the case in the applications) we can recover
. With arbitrary , this result is optimal. The Theorem, however, states that with random measurement error (which often the case in the applications) we can recover 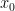 with even higher accuracy
with even higher accuracy  with high probability using the Dantzig selector , which can be computed using linear programming. The error in the Theorem is optimal up to the constant and
with high probability using the Dantzig selector , which can be computed using linear programming. The error in the Theorem is optimal up to the constant and  factors.
factors.
Links: Free arxiv version of the original paper is here, journal version is here.
Go to the list of all theorems
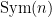 (group of permutations of n symbols), notation
(group of permutations of n symbols), notation 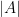 for the number of elements in a finite set
for the number of elements in a finite set  , let
, let 
 is the number of edges between S and its complement.
is the number of edges between S and its complement. 
 -expanders if
-expanders if  for all n.
for all n. such that every
such that every 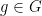 can be written as a finite product of elements of S and their inverses. The (undirected) Cayley graph
can be written as a finite product of elements of S and their inverses. The (undirected) Cayley graph  is the graph whose vertices are elements of G, and vertices
is the graph whose vertices are elements of G, and vertices  are connected by edge if
are connected by edge if  or
or  for some
for some  .
.  such that the following holds. For every n there exists a generating set
such that the following holds. For every n there exists a generating set  of size at most L of the symmetric group
of size at most L of the symmetric group  form a family of
form a family of  if
if  is a multiple of s.
is a multiple of s. is called a covering system if there exist integers
is called a covering system if there exist integers  such that each integer n satisfies at least one of the congruences
such that each integer n satisfies at least one of the congruences  .
. , such that inequality
, such that inequality  holds for any covering system S with
holds for any covering system S with  .
.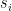 greater than N. In 1973, Erdős and Selfridge conjectured that this is not true if we also require that sum of reciprocals
greater than N. In 1973, Erdős and Selfridge conjectured that this is not true if we also require that sum of reciprocals  of elements of S is bounded by some constant B. The Theorem confirms this conjecture. In particular, this implies that for any number
of elements of S is bounded by some constant B. The Theorem confirms this conjecture. In particular, this implies that for any number  and N sufficiently large, depending on K, there is no covering system S with all
and N sufficiently large, depending on K, there is no covering system S with all ![(N,KN]](https://s0.wp.com/latex.php?latex=%28N%2CKN%5D&bg=ffffff&fg=000000&s=0&c=20201002) . In a
. In a  , thus solving the original Erdős problem.
, thus solving the original Erdős problem.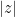 for the absolute value of a complex number
for the absolute value of a complex number  , function in a complex variable, meromorphic function
, function in a complex variable, meromorphic function  , poles of
, poles of  ,
,  notation, big O notation, notation
notation, big O notation, notation  if
if  .
. , let
, let  be the number of poles
be the number of poles 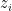 of
of  . The Nevanlinna characteristic
. The Nevanlinna characteristic  of
of  , where
, where  and
and  . The order of a meromorphic function
. The order of a meromorphic function  .
. , any fixed complex number
, any fixed complex number  , and any
, and any  .
. as
as  varies. The Theorem implies that
varies. The Theorem implies that  for finite order meromorphic functions. The authors demonstrate various applications of this result to, for example, difference equations.
for finite order meromorphic functions. The authors demonstrate various applications of this result to, for example, difference equations. .
. given by
given by  , and two vertices are connected by an edge if and only if the distance between them is
, and two vertices are connected by an edge if and only if the distance between them is  . Assume that each vertex of G, independently of other vertices, (i) is coloured black or white at time
. Assume that each vertex of G, independently of other vertices, (i) is coloured black or white at time 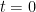 , with probability
, with probability  for each colour, (ii) generate a random variable
for each colour, (ii) generate a random variable  according to exponential distribution with parameter
according to exponential distribution with parameter  , wait for time
, wait for time 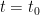 , graph G has an infinite connected subgraph consisting on only white vertices, we say that percolation occurs. Let
, graph G has an infinite connected subgraph consisting on only white vertices, we say that percolation occurs. Let 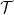 be the set of all times
be the set of all times ![t\in[0,1]](https://s0.wp.com/latex.php?latex=t%5Cin%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) at which percolation occurs.
at which percolation occurs. , the probability that percolation occurs at time
, the probability that percolation occurs at time  . The Theorem states, however, that, with probability
. The Theorem states, however, that, with probability  of vectors with r integer components, notation
of vectors with r integer components, notation  for set
for set  , where
, where  ,
,  , and
, and 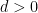 is an integer.
is an integer. is explicitly computable if there is an algorithm which takes
is explicitly computable if there is an algorithm which takes  as an input and returns N as an output.
as an input and returns N as an output. , every positive integer r, and every finite subset
, every positive integer r, and every finite subset  , such that every subset
, such that every subset  of size at least
of size at least  has a subset of the form
has a subset of the form  such that every subset of the set
such that every subset of the set  of size at least
of size at least 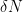 contains an arithmetic progression of length k. In a paper submitted in 2000, Gowers
contains an arithmetic progression of length k. In a paper submitted in 2000, Gowers  , where
, where  . The statement in the Theorem is a multidimensional version of Szemeredi’s theorem. The existence of
. The statement in the Theorem is a multidimensional version of Szemeredi’s theorem. The existence of  required in the Theorem was first proved by Furstenberg and Katznelson in 1978, but without any explicit algorithm how to actually compute this N. The Theorem provides such an algorithm.
required in the Theorem was first proved by Furstenberg and Katznelson in 1978, but without any explicit algorithm how to actually compute this N. The Theorem provides such an algorithm. .
. , and any integer coefficients
, and any integer coefficients  , the system of equations
, the system of equations  has a non-trivial solution in integers if and only if it has a non-trivial solution in the 7-adic field.
has a non-trivial solution in integers if and only if it has a non-trivial solution in the 7-adic field. with integer coefficients
with integer coefficients 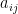 . For cubic equations, the Hasse principle fails in general, but The Theorem implies that it holds for the system
. For cubic equations, the Hasse principle fails in general, but The Theorem implies that it holds for the system  , and fails for
, and fails for  , hence the condition
, hence the condition 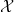 , the notion of “almost all”
, the notion of “almost all” 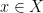 , notation
, notation  for n-fold composiition
for n-fold composiition  of map
of map  , notation
, notation  for the preimage of
for the preimage of  , integration on X, notation
, integration on X, notation  for set of functions
for set of functions  such that
such that  , notation
, notation  for sequence
for sequence  .
. is a probability space X, together with map
is a probability space X, together with map  for all
for all  , and (ii) for any
, and (ii) for any  , either
, either  or
or  . A sequence
. A sequence  and
and  , such that the limit
, such that the limit  fails to exist for all
fails to exist for all  .
. is L1-universally bad.
is L1-universally bad. exists for almost all
exists for almost all  ). An important research direction is to understand for which sequences
). An important research direction is to understand for which sequences  for some
for some  , and asked if the same is true for all
, and asked if the same is true for all  of sequences
of sequences 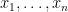 such that each
such that each  is either
is either 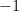 or
or ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=000000&s=0&c=20201002) for set
for set 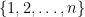 , notation
, notation  for the sign of real number x.
for the sign of real number x. . Denote
. Denote ![E[f] = \frac{1}{2^n}\sum\limits_{x\in \{-1,1\}^n}f(x)](https://s0.wp.com/latex.php?latex=E%5Bf%5D+%3D+%5Cfrac%7B1%7D%7B2%5En%7D%5Csum%5Climits_%7Bx%5Cin+%5C%7B-1%2C1%5C%7D%5En%7Df%28x%29&bg=ffffff&fg=000000&s=0&c=20201002) the average value of f. For
the average value of f. For ![i\in [n]](https://s0.wp.com/latex.php?latex=i%5Cin+%5Bn%5D&bg=ffffff&fg=000000&s=0&c=20201002) , let
, let  be the number of
be the number of  , sich that
, sich that  . Ratio
. Ratio  is called the influence of i. Equivalently,
is called the influence of i. Equivalently, ![\text{Inf}_i(f) = \sum\limits_{S\subset[n], i\in S}\hat{f}(S)^2](https://s0.wp.com/latex.php?latex=%5Ctext%7BInf%7D_i%28f%29+%3D+%5Csum%5Climits_%7BS%5Csubset%5Bn%5D%2C+i%5Cin+S%7D%5Chat%7Bf%7D%28S%29%5E2&bg=ffffff&fg=000000&s=0&c=20201002) , where
, where ![\hat{f}(S)=\frac{1}{2^n}\sum\limits_{x\in \{-1,1\}^n}\left[f(x)\prod\limits_{i\in S}x_i\right]](https://s0.wp.com/latex.php?latex=%5Chat%7Bf%7D%28S%29%3D%5Cfrac%7B1%7D%7B2%5En%7D%5Csum%5Climits_%7Bx%5Cin+%5C%7B-1%2C1%5C%7D%5En%7D%5Cleft%5Bf%28x%29%5Cprod%5Climits_%7Bi%5Cin+S%7Dx_i%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002) . For
. For  , the noise stability of f is
, the noise stability of f is ![S_\rho(f)=\sum\limits_{S\subset[n]}\rho^{|S|}\hat{f}(S)^2](https://s0.wp.com/latex.php?latex=S_%5Crho%28f%29%3D%5Csum%5Climits_%7BS%5Csubset%5Bn%5D%7D%5Crho%5E%7B%7CS%7C%7D%5Chat%7Bf%7D%28S%29%5E2&bg=ffffff&fg=000000&s=0&c=20201002) .
. and
and  such that if
such that if ![E[f]=0](https://s0.wp.com/latex.php?latex=E%5Bf%5D%3D0&bg=ffffff&fg=000000&s=0&c=20201002) and
and  for all i, then
for all i, then  .
. (we may assume that n is odd to guarantee that
(we may assume that n is odd to guarantee that  ), we have
), we have  . Thus, the Theorem states that the majority function has (in the limit
. Thus, the Theorem states that the majority function has (in the limit 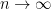 and up to
and up to  of integers, infinite sum
of integers, infinite sum  , Cantor set.
, Cantor set.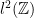 be the set of all infinite sequences
be the set of all infinite sequences  such that
such that  . A map
. A map  is called invertible if for every
is called invertible if for every  there exists a unique
there exists a unique  such that
such that  . The almost Mathieu operator is the map
. The almost Mathieu operator is the map  mapping each
mapping each  , where
, where  ,
,  , and
, and  are real parameters, called coupling, frequency, and phase, respectively.
are real parameters, called coupling, frequency, and phase, respectively.  for which map
for which map  given by
given by  ,
,  , is not invertible is called the spectrum of H.
, is not invertible is called the spectrum of H.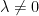 .
.