You need to know: Euclidean space  , norms
, norms  and
and  in , support of vector
in , support of vector  (subset
(subset  such that
such that 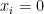 for all
for all  ),
),  matrix, matrix multiplication, big O notation.
matrix, matrix multiplication, big O notation.
Background: For  let
let  , where A is matrix (
, where A is matrix ( ) and
) and  . Let
. Let  be a solution to the problem
be a solution to the problem  subject to
subject to  for some
for some 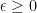 (this is called
(this is called  -regularisation problem).
-regularisation problem).
For , let  be
be  submatrix of A formed from the columns of A corresponding to the indices in T. For
submatrix of A formed from the columns of A corresponding to the indices in T. For  , let
, let  be the smallest number such that inequalities
be the smallest number such that inequalities  hold for all T with
hold for all T with  and all
and all  .
.
The Theorem: On 3rd March 2005, Emmanuel Candes, Justin Romberg, and Terence Tao submitted to arxiv and Communications on Pure and Applied Mathematics a paper in which they proved the following result. Let A be matrix (), and let S be such that  . Then for any supported on
. Then for any supported on  with
with  and any such that
and any such that  , we have
, we have  , where the constant
, where the constant  depends only on
depends only on  . For example,
. For example,  for
for  and
and  for
for  .
.
Short context: Vectors with few non-zero entries are called sparse and may represent, for example, image or signal in various applications. Vector is the result of n measurements (given by rows of A) with error e. Given y, we then try to recover 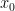 by solving the -regularisation problem. The Theorem states that its solution is close to . In particular, if the measurements are exact (
by solving the -regularisation problem. The Theorem states that its solution is close to . In particular, if the measurements are exact ( ) then
) then  . The authors show that the condition in the Theorem holds for almost all matrices A with unit-normed columns if
. The authors show that the condition in the Theorem holds for almost all matrices A with unit-normed columns if  , hence, with high probability, we can recover after just
, hence, with high probability, we can recover after just  random measurements. In an earlier work, Donoho proved the existence of a recovery procedure with similar properties, while the Theorem states that a concrete efficient algorithm (-regularisation) does the job, even for inaccurate measurements. The error
random measurements. In an earlier work, Donoho proved the existence of a recovery procedure with similar properties, while the Theorem states that a concrete efficient algorithm (-regularisation) does the job, even for inaccurate measurements. The error  in the Theorem is essentially optimal.
in the Theorem is essentially optimal.
Links: Free arxiv version of the original paper is here, journal version is here.
Go to the list of all theorems
 of integers, greatest common divisor (gcd) of 2 integers, set
of integers, greatest common divisor (gcd) of 2 integers, set 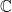 of complex numbers,
of complex numbers,  notation.
notation. is called a Dirichlet character modulo integer
is called a Dirichlet character modulo integer  if (i)
if (i)  for all n, (ii) if
for all n, (ii) if  then
then  ; if
; if  then
then  , and (iii)
, and (iii)  for all integers m and n. An example is character
for all integers m and n. An example is character  such that
such that  whenever
whenever  otherwise. This character is called principal and all other characters – nonprincipal. The order of a Dirichlet character
otherwise. This character is called principal and all other characters – nonprincipal. The order of a Dirichlet character  is the least positive integer m such that
is the least positive integer m such that  for all n.
for all n.  such that
such that  whenever
whenever  and
and 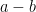 is a multiple of d.
is a multiple of d.  .
. where
where  , and
, and 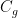 is a constant depending only on g.
is a constant depending only on g. for any nonprincipal Dirichlet character
for any nonprincipal Dirichlet character  in terms of q is possible. The Theorem provides an improved bound for characters of odd, bounded order.
in terms of q is possible. The Theorem provides an improved bound for characters of odd, bounded order. .
. be the number of labelled planar graphs on n vertices. We write
be the number of labelled planar graphs on n vertices. We write  if
if  .
. , where
, where  and
and  are explicit constants.
are explicit constants. , but much more difficult to actually compute this limit. Many researchers provided better and better lower and upper bounds for
, but much more difficult to actually compute this limit. Many researchers provided better and better lower and upper bounds for 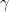 , with the best (before 2005) bounds
, with the best (before 2005) bounds  by Bender, Gao and Wormald and
by Bender, Gao and Wormald and  by Bonichon et.al. The Theorem provides an exact analytical expression for
by Bonichon et.al. The Theorem provides an exact analytical expression for 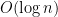 .
. 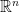 , inner product
, inner product  in
in 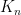 be the minimal constant such that for every
be the minimal constant such that for every 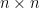 matrix with entries
matrix with entries 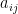 and every unit vectors
and every unit vectors  in
in  for which
for which  . Constant
. Constant  , see
, see 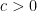 such that
such that  for all n.
for all n. for some constant C. Later, Megretski asked if this can be improved to
for some constant C. Later, Megretski asked if this can be improved to  . In 2004, Charikar and Wirth derived from inequality
. In 2004, Charikar and Wirth derived from inequality  of square matrix M, singular square matrix (matrix with determinant
of square matrix M, singular square matrix (matrix with determinant  ), basic probability theory, independent and identically distributed (i.i.d.) random variables,
), basic probability theory, independent and identically distributed (i.i.d.) random variables, 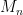 be a random
be a random 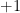 or
or 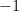 with probabilities
with probabilities  ). Let
). Let  be the probability that
be the probability that  as
as 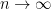 .
. has attracted considerable attention in literature. In 1967, Komlós proved that
has attracted considerable attention in literature. In 1967, Komlós proved that  . In 1995, Kahn, Komlós, and Szemerédi proved that
. In 1995, Kahn, Komlós, and Szemerédi proved that  . This was later improved by Tao and Vu to
. This was later improved by Tao and Vu to  . The Theorem provides a much better upper bound.
. The Theorem provides a much better upper bound. in a group, subgroup, isomorphic groups, conjugate elements in a group, conjugacy classes, countable and uncountable sets, notation
in a group, subgroup, isomorphic groups, conjugate elements in a group, conjugacy classes, countable and uncountable sets, notation  for the number of elements in finite set S.
for the number of elements in finite set S. such that every
such that every 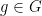 can be written as a finite product of elements of S and their inverses. Group G is called finitely generated if it has finite generating set. In particular, it is called 2-generated if it has generating set S with
can be written as a finite product of elements of S and their inverses. Group G is called finitely generated if it has finite generating set. In particular, it is called 2-generated if it has generating set S with  . We say that group H can be embedded into group G, if G has a subgroup isomorphic to H. The order of non-identity element
. We say that group H can be embedded into group G, if G has a subgroup isomorphic to H. The order of non-identity element 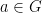 is the lowest positive integer n such that
is the lowest positive integer n such that  , with the convention that the order is infinite if no such n exists. For a group G, let
, with the convention that the order is infinite if no such n exists. For a group G, let  be the set of all (finite) positive integers n such that there exists an element
be the set of all (finite) positive integers n such that there exists an element  of order n.
of order n. .
. which has exactly 2 conjugacy classes. The Theorem also implies that for any integer
which has exactly 2 conjugacy classes. The Theorem also implies that for any integer  there are uncountably many pairwise nonisomorphic finitely generated groups with exactly n conjugacy classes.
there are uncountably many pairwise nonisomorphic finitely generated groups with exactly n conjugacy classes.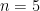 are called quintic. For
are called quintic. For  , let
, let  denotes the number of non-isomorphic number fields of degree n with absolute value of the discriminant at most X. Also, let
denotes the number of non-isomorphic number fields of degree n with absolute value of the discriminant at most X. Also, let 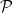 be the set of prime numbers.
be the set of prime numbers. exists and is equal to
exists and is equal to  .
. for every fixed n, but, before 2004, this was known only for
for every fixed n, but, before 2004, this was known only for  (see
(see 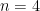
 in
in  , infimum, supremum, big O notation.
, infimum, supremum, big O notation. be orthonormal basis in
be orthonormal basis in  (where
(where  and
and  are constants) be the set of vectors whose coefficients
are constants) be the set of vectors whose coefficients  in this basis are not too large. Let
in this basis are not too large. Let  has the form
has the form  for some vectors
for some vectors  ,
,  be arbitrary operator, and
be arbitrary operator, and 
 and
and  there is a constant
there is a constant  , such that
, such that  whenever
whenever  .
.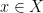
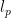 -sparse. Such vectors arise in numerous applications, for example, x may represent an image (e.g. medical image) with m pixels. Vectors
-sparse. Such vectors arise in numerous applications, for example, x may represent an image (e.g. medical image) with m pixels. Vectors  the result of n measurements,
the result of n measurements,  is the worst-case error of this procedure, and
is the worst-case error of this procedure, and  is the minimal worst-case error we can achieve using non-adaptive procedure, that is, the same for all x. The Theorem states that we can achieve
is the minimal worst-case error we can achieve using non-adaptive procedure, that is, the same for all x. The Theorem states that we can achieve  error, where
error, where  , using just
, using just  non-adaptive measurements. This methodology is called compressed sensing and has dramatic implications in, for example, fast reconstruction of medical images. The paper is one of the most cited (if not the most cited) mathematical paper of the 21st century.
non-adaptive measurements. This methodology is called compressed sensing and has dramatic implications in, for example, fast reconstruction of medical images. The paper is one of the most cited (if not the most cited) mathematical paper of the 21st century. in
in  , where
, where  is a basis for
is a basis for  is
is  or
or  , denote
, denote  .
.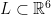 , and any
, and any  , there is a
, there is a  such that
such that  .
. , we have
, we have  . The conjecture is interesting in its own, and also has number-theoretic consequences. Before 2004, it was known for
. The conjecture is interesting in its own, and also has number-theoretic consequences. Before 2004, it was known for  . The Theorem proves it for
. The Theorem proves it for 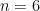 .
.