You need to know: Basic geometry (distance in the plane, vector addition), limits, connected graph.
Background: Consider n autonomous agents (points) which are moving in the plane with the same speed but with different directions. Fix constant 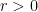


The Theorem: On 4th March 2002, Ali Jadbabaie, Jie Lin, and Stephen Moore submitted to IEEE Transactions on Automatic Control a paper in which they proved the following result. Assume that, in the model described above, there exists an infinite sequence of continuous, non-empty, bounded, non-intersecting time-intervals 

Short context: Coordination of groups of mobile autonomous agents in an important topic which attracted a lot of attention in the literature. It has applications in physics (e.g. the study of active matter), machine learning, etc. In 1995, Vicsek, Czirok, Ben Jacob, Cohen, and Schochet suggested the model described above, and performed a number of numerical simulations demonstrating that, after some time, the agents start moving in the same direction, despite the absence of central coordination. The Theorem provides a theoretical explanation for this observation.
Links: The original paper is available here.
 of points
of points  with integer coefficients, probability, independent random variables, exponential distribution, covariance
with integer coefficients, probability, independent random variables, exponential distribution, covariance  of random variables X and Y.
of random variables X and Y. , let us put, for each
, let us put, for each  , a particle in site x, independently and with probability
, a particle in site x, independently and with probability  . Then, for each particle p, independently generate a random variable
. Then, for each particle p, independently generate a random variable  from exponential distribution, wait for time
from exponential distribution, wait for time  , respectively, provided that the target site is unoccupied (and otherwise stay). This action is then repeated and performed in parallel for all particles. We call this asymmetric simple exclusion process (ASEP). For any
, respectively, provided that the target site is unoccupied (and otherwise stay). This action is then repeated and performed in parallel for all particles. We call this asymmetric simple exclusion process (ASEP). For any  be the number of particles (which can be
be the number of particles (which can be  or
or  ) in position x at time t. Next define
) in position x at time t. Next define  , where
, where 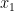 is the first coordinate of x.
is the first coordinate of x. such that, for sufficiently small
such that, for sufficiently small 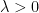 ,
, 
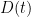 defined above is known as diffusion coefficient, and understanding how fast
defined above is known as diffusion coefficient, and understanding how fast 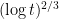 for large t, and can therefore be called “
for large t, and can therefore be called “ on set
on set 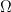 , norm
, norm  for functions on
for functions on 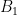 be the set of all functions
be the set of all functions ![f:\Omega \to [-1,1]](https://s0.wp.com/latex.php?latex=f%3A%5COmega+%5Cto+%5B-1%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) , and let A be any subset of
, and let A be any subset of  the covering number of A, that is, the minimal number of functions whose linear combination can approximate any function in A within an error t in the
the covering number of A, that is, the minimal number of functions whose linear combination can approximate any function in A within an error t in the  of
of  with
with  , one can find a function
, one can find a function  with
with  if
if  but
but  if
if  . The shattering (or combinatorial) dimension
. The shattering (or combinatorial) dimension  of A is the maximal cardinality of a set t-shattered by A.
of A is the maximal cardinality of a set t-shattered by A. where K and c are positive absolute constants.
where K and c are positive absolute constants. , volume in
, volume in 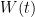 be standard Wiener process in
be standard Wiener process in 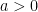 and
and  , let
, let ![W_a(t) = \{ x \in {\mathbb R}^d \,|\,\exists s \in [0,t] : \rho(x,W(s)) \leq a \}](https://s0.wp.com/latex.php?latex=W_a%28t%29+%3D+%5C%7B+x+%5Cin+%7B%5Cmathbb+R%7D%5Ed+%5C%2C%7C%5C%2C%5Cexists+s+%5Cin+%5B0%2Ct%5D+%3A+%5Crho%28x%2CW%28s%29%29+%5Cleq+a+%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002) , where
, where 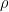 is the distance in
is the distance in  is known as Wiener sausage. Let
is known as Wiener sausage. Let  be the intersection of two Wiener sausages corresponding to two independent Wiener processes starting at origin, and let
be the intersection of two Wiener sausages corresponding to two independent Wiener processes starting at origin, and let  be its (d-dimensional) volume.
be its (d-dimensional) volume. ,
, where P denotes the probability, and
where P denotes the probability, and  is some constant depending on a, d, and b. Similarly,
is some constant depending on a, d, and b. Similarly, .
. be fixed and denote
be fixed and denote  . The Theorem implies that, for large t,
. The Theorem implies that, for large t,  decays as
decays as  for
for  . In other words, the probability that Wiener sausages intersection volume is large (larger than t after time bt) decays exponentially fast in t, with constant in the exponent
. In other words, the probability that Wiener sausages intersection volume is large (larger than t after time bt) decays exponentially fast in t, with constant in the exponent  . This gives us a good idea how the distribution of
. This gives us a good idea how the distribution of  looks like. The Theorem resolves open questions asked by Khanin, Mazel, Shlosman, and Sinai in 1994.
looks like. The Theorem resolves open questions asked by Khanin, Mazel, Shlosman, and Sinai in 1994. of set S (that is, the number of elements in it), sum
of set S (that is, the number of elements in it), sum  and product
and product  notations.
notations. be a set of k distinct integers, and let
be a set of k distinct integers, and let  and
and  be the set of all possible simple sums and products of elements of A, respectively. Let
be the set of all possible simple sums and products of elements of A, respectively. Let  .
. there is a
there is a  such that
such that  for all
for all 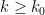 .
. and set of products
and set of products  cannot both be small. Specifically, they conjectured that
cannot both be small. Specifically, they conjectured that  grows faster than any polynomial in k, that is, for any d, there exists a constant
grows faster than any polynomial in k, that is, for any d, there exists a constant  such that
such that  for any
for any  . The Theorem implies this conjecture and in fact provides a stronger lower bound on
. The Theorem implies this conjecture and in fact provides a stronger lower bound on  for some constant c, the bound in the Theorem is the best possible up to the constant factor in the exponent.
for some constant c, the bound in the Theorem is the best possible up to the constant factor in the exponent. is a vector in
is a vector in  for some m, with norm
for some m, with norm  . Let
. Let  be the number of steps A works at input
be the number of steps A works at input  , where
, where  is the set of all possible inputs of bit-length n. The smoothed complexity of A is
is the set of all possible inputs of bit-length n. The smoothed complexity of A is ![f(n,\sigma) = \max\limits_{x\in X_n} E_g[C_A(x+(\sigma||x||)g]](https://s0.wp.com/latex.php?latex=f%28n%2C%5Csigma%29+%3D+%5Cmax%5Climits_%7Bx%5Cin+X_n%7D+E_g%5BC_A%28x%2B%28%5Csigma%7C%7Cx%7C%7C%29g%5D&bg=ffffff&fg=000000&s=0&c=20201002) , where
, where  is a vector of Gaussian random variables of mean
is a vector of Gaussian random variables of mean  , and
, and  is the corresponding expectation. We say that an algorithm A has polynomial smoothed complexity if
is the corresponding expectation. We say that an algorithm A has polynomial smoothed complexity if  is bounded by a polynomial in n and
is bounded by a polynomial in n and  .
. of natural numbers, complex numbers, notation
of natural numbers, complex numbers, notation ![{\mathbb C}[x]](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb+C%7D%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002) for the set of polynomials with complex coefficients.
for the set of polynomials with complex coefficients. such that
such that  for some
for some 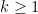 and complex numbers
and complex numbers  .
. and
and  such that
such that  is an integer for infinitely many values of n, there exists a nonzero polynomial
is an integer for infinitely many values of n, there exists a nonzero polynomial ![P(X) \in {\mathbb C}[X]](https://s0.wp.com/latex.php?latex=P%28X%29+%5Cin+%7B%5Cmathbb+C%7D%5BX%5D&bg=ffffff&fg=000000&s=0&c=20201002) and positive integers
and positive integers  such that both sequences
such that both sequences  and
and  are linear recurrences.
are linear recurrences. is an integer for all large n, then
is an integer for all large n, then 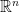 , notation
, notation  for norm in
for norm in  , ball
, ball  with centre in the origin and radius R, volume
with centre in the origin and radius R, volume  of this ball, notation
of this ball, notation 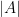 for the number of elements in finite set A, scalar product
for the number of elements in finite set A, scalar product  in
in 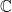 of complex numbers,
of complex numbers,  , Fourier transform
, Fourier transform  of an integrable function
of an integrable function  .
. for all distinct
for all distinct  is called a sphere packing. The center density of a sphere packing S is
is called a sphere packing. The center density of a sphere packing S is  . The upper density of S is
. The upper density of S is  .
. is called admissible if there exist positive constants
is called admissible if there exist positive constants  ,
, 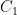 ,
, 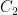 such that
such that  and
and  for all
for all  .
. for
for  , and (ii)
, and (ii)  (which implies that
(which implies that  is real) for all
is real) for all  . Then the center density of any sphere packing in
. Then the center density of any sphere packing in  .
. . The Theorem provides a general method for proving upper bounds for sphere packing densities. In the same paper, Cohn and Elkies used the Theorem to derive improved upper bounds in dimensions
. The Theorem provides a general method for proving upper bounds for sphere packing densities. In the same paper, Cohn and Elkies used the Theorem to derive improved upper bounds in dimensions  . In particular, for
. In particular, for  , they derive bound
, they derive bound  , where
, where  is the density of densest known packing. In later works (see
is the density of densest known packing. In later works (see  for set difference,
for set difference,  notation for supremum, complex plane
notation for supremum, complex plane 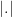 of a complex number, analytic function, notation
of a complex number, analytic function, notation  for
for  .
. where the supremum is taken over all analytic functions
where the supremum is taken over all analytic functions  such that
such that  on
on  , and
, and  .
. for all compact sets E and F. In other words, the analytic capacity is semiadditive.
for all compact sets E and F. In other words, the analytic capacity is semiadditive. with compact union.
with compact union. in
in  with respect to a hyperplane H going through the origin is the set of all midpoints of line segments
with respect to a hyperplane H going through the origin is the set of all midpoints of line segments 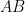 with
with  and
and  being a reflection of some point in S with respect to H.
being a reflection of some point in S with respect to H. and any convex body
and any convex body  , there exist
, there exist  Minkowski symmetrizations
Minkowski symmetrizations  such that the convex body
such that the convex body  contains a ball of radius
contains a ball of radius 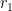 , but is contained in a ball of radius
, but is contained in a ball of radius 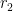 , with
, with  , where c is a universal constant, independent of n and S.
, where c is a universal constant, independent of n and S. Minkowski symmetrizations selected at random suffices to transform any convex body in
Minkowski symmetrizations selected at random suffices to transform any convex body in 